
从0到1搭建大数据平台之调度系统(建议收藏)
共 2943字,需浏览 6分钟
· 2020-07-28

目前大数据平台经常会用来跑一些批任务,跑批处理当然就离不开定时任务。比如定时抽取业务数据库的数据,定时跑hive/spark任务,定时推送日报、月报指标数据。任务调度系统已经俨然成为了大数据处理平台不可或缺的一部分。
一、原始任务调度
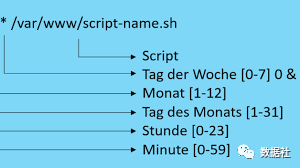
记得第一次参与大数据平台从无到有的搭建,最开始任务调度就是用的Crontab,分时日月周,各种任务脚本配置在一台主机上。crontab 使用非常方便,配置也很简单。刚开始任务很少,用着还可以,每天起床巡检一下日志。随着任务越来越多,出现了任务不能在原来计划的时间完成,出现了上级任务跑完前,后面依赖的任务已经起来了,这时候没有数据,任务就会报错,或者两个任务并行跑了,出现了错误的结果。排查任务错误原因越来麻烦,各种任务的依赖关系越来越负责,最后排查任务问题就行从一团乱麻中,一根一根梳理出每天麻绳。crontab虽然简单,稳定,但是随着任务的增加和依赖关系越来越复杂,已经完全不能满足我们的需求了,这时候就需要建设自己的调度系统了。
二、调度系统
多个任务单元之间往往有着强依赖关系,上游任务执行并成功,下游任务才可以执行。比如上游任务1结束后拿到结果,下游任务2、任务3需结合任务1的结果才能执行,因此下游任务的开始一定是在上游任务成功运行拿到结果之后才可以开始。而为了保证数据处理结果的准确性,就必须要求这些任务按照上下游依赖关系有序、高效的执行,最终确保能按时正常生成业务指标。
Airflow
Apache Airflow是一种功能强大的工具,可作为任务的有向无环图(DAG)编排、任务调度和任务监控的工作流工具。Airflow在DAG中管理作业之间的执行依赖,并可以处理作业失败,重试和警报。开发人员可以编写Python代码以将数据转换为工作流中的操作。
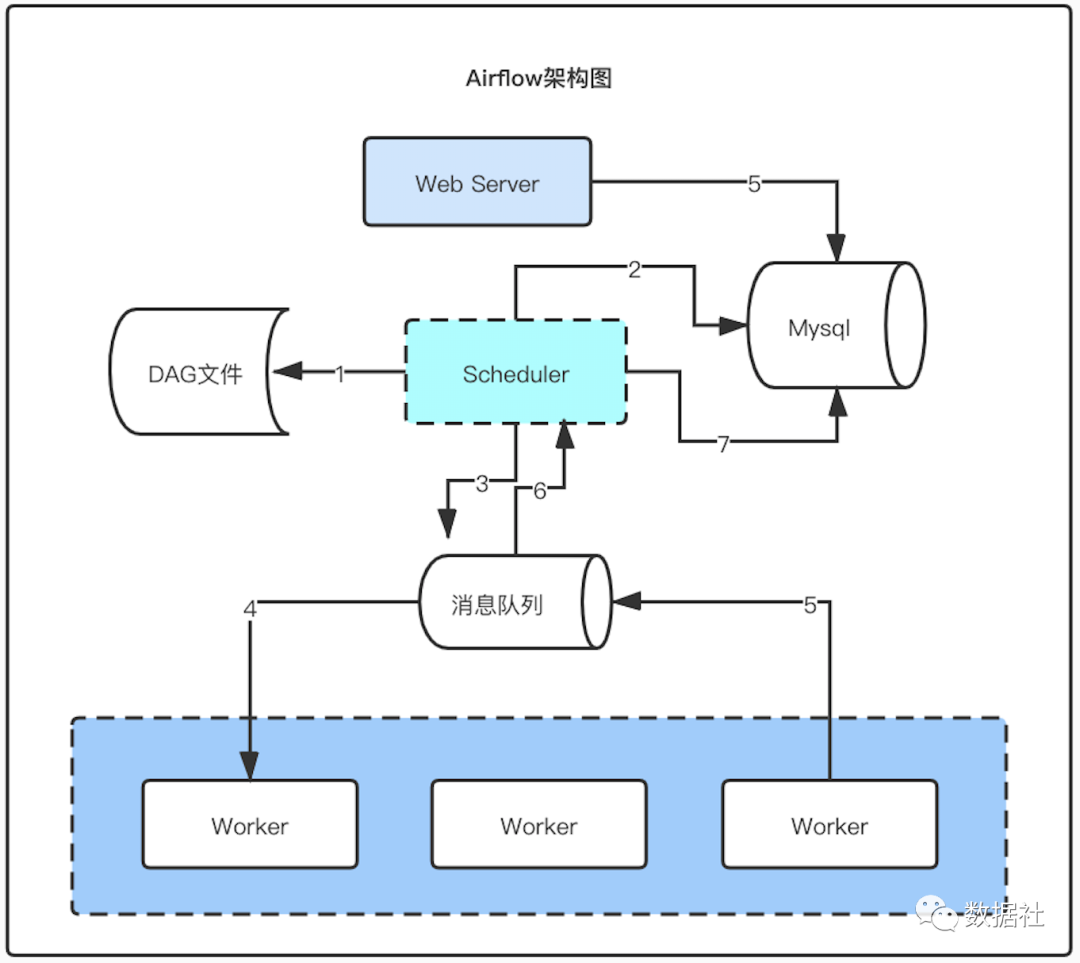
主要有如下几种组件构成:
web server: 主要包括工作流配置,监控,管理等操作
scheduler: 工作流调度进程,触发工作流执行,状态更新等操作
消息队列:存放任务执行命令和任务执行状态报告
worker: 执行任务和汇报状态
mysql: 存放工作流,任务元数据信息
具体执行流程:
scheduler扫描dag文件存入数据库,判断是否触发执行
到达触发执行时间的dag,生成dag_run,task_instance 存入数据库
发送执行任务命令到消息队列
worker从队列获取任务执行命令执行任务
worker汇报任务执行状态到消息队列
schduler获取任务执行状态,并做下一步操作
schduler根据状态更新数据库
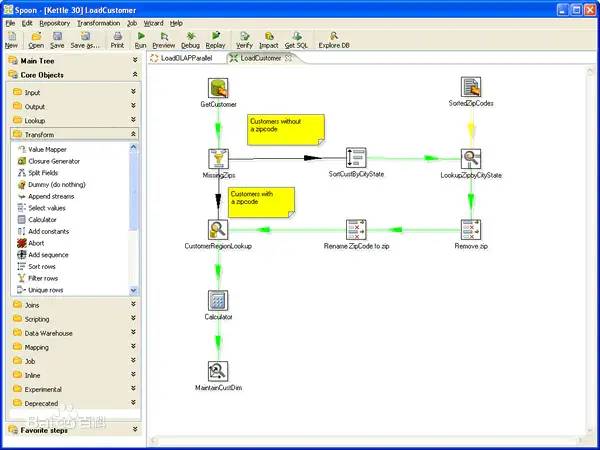
Kettle
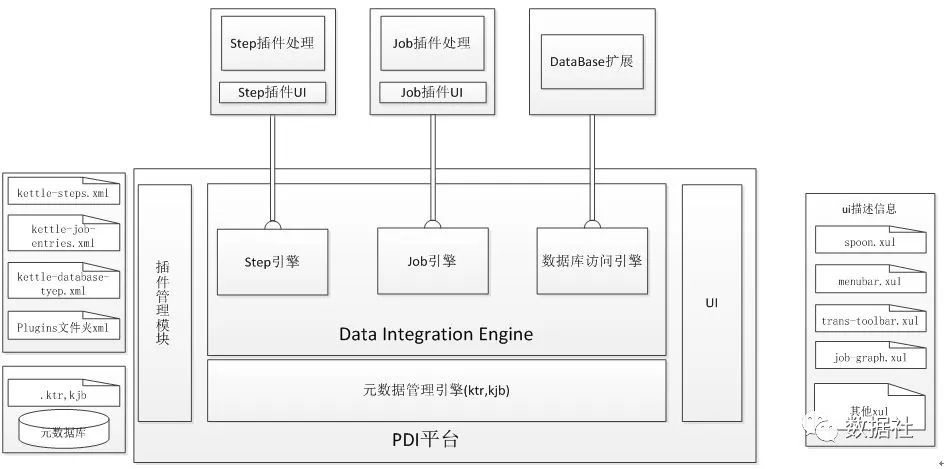
将各个任务操作组件拖放到工作区,kettle支持各种常见的数据转换。此外,用户可以将Python,Java,JavaScript和SQL中的自定义脚本拖放到画布上。kettle可以接受许多文件类型作为输入,还可以通过JDBC,ODBC连接到40多个数据库,作为源或目标。社区版本是免费的,但提供的功能比付费版本少。
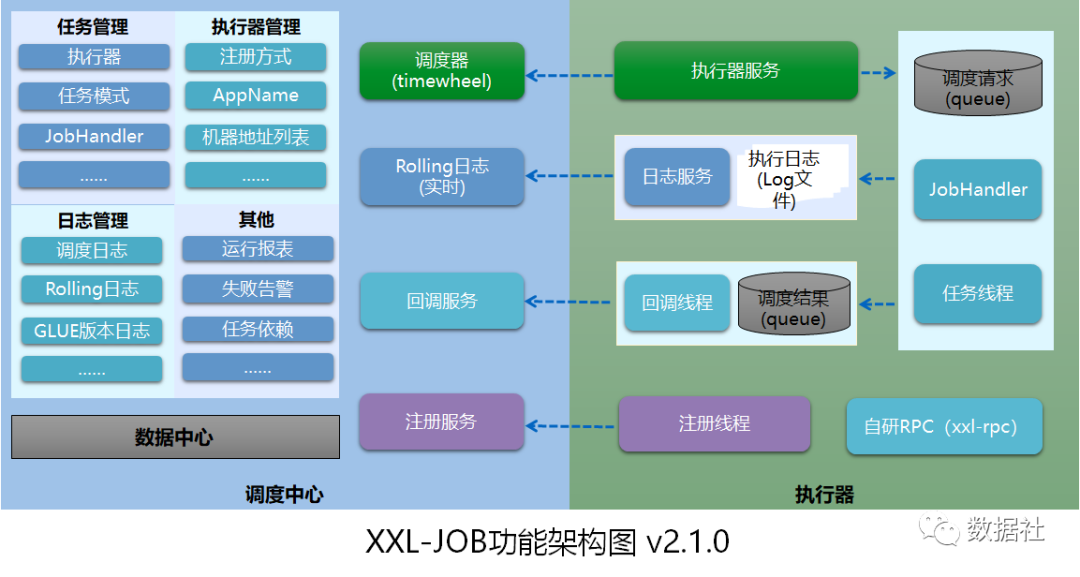
XXL-JOB
XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。将调度行为抽象形成“调度中心”公共平台,而平台自身并不承担业务逻辑,“调度中心”负责发起调度请求;将任务抽象成分散的JobHandler,交由“执行器”统一管理,“执行器”负责接收调度请求并执行对应的JobHandler中业务逻辑;因此,“调度”和“任务”两部分可以相互解耦,提高系统整体稳定性和扩展性。(后来才知道XXL是作者名字拼音首字母缩写)
调度系统开源工具有很多,可以结合自己公司人员的熟悉程度和需求选择合适的进行改进。
三、如何设计调度系统
调度平台其实需要解决三个问题:任务编排、任务执行和任务监控。
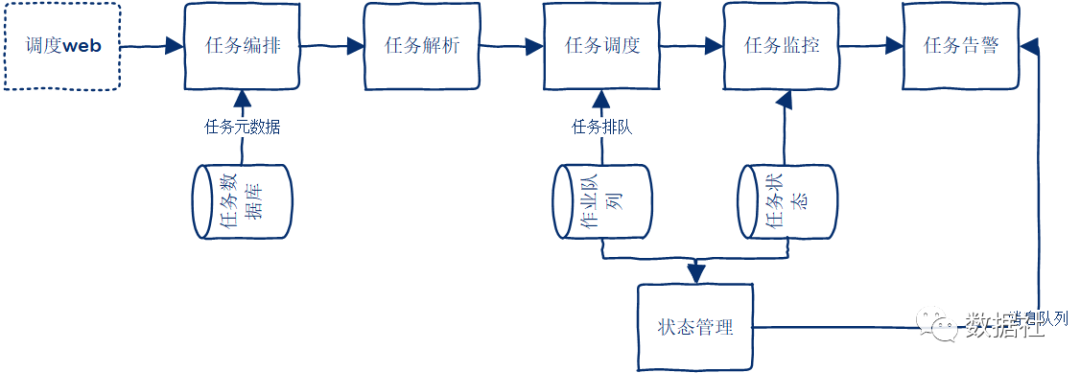
任务编排,采用调用外部编排服务的方式,主要考虑的是编排需要根据业务的一些属性进行实现,所以将易变的业务部分从作业调度平台分离出去。如果后续有对编排逻辑进行调整和修改,都无需操作业务作业调度平台。
任务排队,支持多队列排队配置,后期根据不同类型的开发人员可以配置不同的队列和资源,比如面向不同的开发人员需要有不同的服务队列,面向不同的任务也需要有不同的队列优先级支持。通过队列来隔离调度,能够更好地满足具有不同需求的用户。不同队列的资源不同,合理的利用资源,达到业务价值最大化。
任务调度,是对任务、以及属于该任务的一组子任务进行调度,为了简单可控起见,每个任务经过编排后会得到一组有序的任务列表,然后对每个任务进行调度。这里面,稍有点复杂的是,任务里还有子任务,子任务是一些处理组件,比如字段转换、数据抽取,子任务需要在上层任务中引用实现调度。任务是调度运行的基本单位。被调度运行的任务会发送到消息队列中,然后等待任务协调计算平台消费并运行任务,这时调度平台只需要等待任务运行完成的结果消息到达,然后对作业和任务的状态进行更新,根据实际状态确定下一次调度的任务。
调度平台设计中还需要注意以下几项:
调度运行的任务需要进行超时处理,比如某个任务由于开发人员设计不合理导致运行时间过长,可以设置任务最大的执行时长,超过最大时长的任务需要及时kill掉,以免占用大量资源,影响正常的任务运行。
控制同时能够被调度的作业的数量,集群资源是有限的,我们需要控制任务的并发量,后期任务上千上万后我们要及时调整任务的启动时间,避免同时启动大量的任务,减少调度资源和计算资源压力;
作业优先级控制,每个业务都有一定的重要级别,我们要有限保障最重要的业务优先执行,优先给与调度资源分配。在任务积压时候,先执行优先级高的任务,保障业务影响最小化。
四、总结
ETL 开发是数据工程师必备的技能之一,在数据仓库、BI等场景中起到重要的作用。但很多从业者连 ETL 对应的英文是什么都不了解,更不要谈对 ETL 的深入解析,这无疑是非常不称职的。做ETL 你可以用任何的编程语言来完成开发,无论是 shell、python、java 甚至数据库的存储过程,只要它最终是让数据完成抽取(E)、转化(T)、加载(L)的效果即可。由于ETL是极为复杂的过程,而手写程序不易管理,所以越来越多的可视化调度编排工具出现了。
不管黑猫白猫,只要能逮住老鼠就是好猫。不管是哪种工具,只要具备高效运行、易于维护两个特点,都是一款好工具。
--end--