
谷歌推出全新强化学习智能体,1秒处理240万帧大幅超越IMPALA

新智元报道
编辑:元子,啸林
【新智元导读】当前的RL技术需要越来越多的训练才能成功学习简单的游戏,这使得迭代研究和产品构想在计算上既昂贵又耗时。近期,一个Google团队提出了一种被称为SEED(可扩展、高效Deep-RL)的现代可扩展强化学习智能体,可扩展到数千台机器,能够以每秒数百万帧的速度进行训练,并显着提高了计算效率。「新智元急聘主笔、高级主任编辑,添加HR微信(Dr-wly)或扫描文末二维码了解详情。」
DeepMind的强化学习研究小组领导人,AlphaGo、AlphaZero的首席研究员及AlphaStar的联合负责人David Silver教授曾经介绍过强化学习的是原则,其中No. 2就是可伸缩性,并认为“算法的可扩展性最终决定了它的成功与否”。从这个角度上看,SEED作为一个在真正大规模架构上的可扩展Deep-RL框架,无疑是RL领域的重要贡献。
SEED火力全开,成本直降80%每秒处理240万帧
传统的可伸缩强化学习框架,比如IMPALA和R2D2,并行运行多个智能体来收集转换,每个智能体都有来自参数服务器(或learner)的自己模型的副本。
这种体系结构需要传输模型参数,以及环境信息,对带宽要求非常高,从而导致成本高昂。Google Brain团队的Espeholt、Marinier及Stanczyk等人提出了一种叫做SEED (Scalable Efficient Deep-RL)的强化学习智能体,具有超强的可伸缩性,能够利用现代加速器来加速数据收集和学习过程,和IMPALA相比,运行成本直接降了80%!
训练AI玩游戏时,SEED RL的处理速度可高达240万帧/秒。让我们以60fps帧数计算,相当一秒处理11小时游戏画面。
传统架构的缺陷
为了便于说明,这里主要和大家已经比较熟悉的IMPALA比较。
IMPALA利用专门用于数值计算的加速器,充分利用了(无)监督学习多年来受益的速度和效率。其体系结构通常分为Actor和learner。Actor通常在CPU上运行,并且在环境中采取的步骤与对模型进行推断之间进行迭代,以预测下一个动作。
通常,Actor会更新推理模型的参数,并且在收集到足够数量的观察结果之后,会将观察结果和动作的轨迹发送给learner,从而对learner进行优化。在这种架构中,learner使用来自数百台机器上的分布式推理的输入在GPU上训练模型。
但IMPALA存在着许多缺点:
1、使用CPU进行神经网络推理,效率低下。而且随着模型变大、运算量变大,问题会越来越严重。2、Actor和Learner之间模型参数的带宽成为性能的瓶颈。3、资源利用效率低,Actor在环境和推理两个任务之间交替进行,而这两个任务的计算要求不同,很难在同一台机器上充分利用资源。
SEED RL具有哪些优势?
SEED RL体系架构解决了以上这些缺点。Actor可以在GPU、TPU这类AI硬件加速器上完成推理,通过确保将模型参数和状态保持在本地来加快推理速度,并避免数据传输瓶颈。与IMPALA体系结构相反,SEED RL中的Actor仅在环境中执行操作。Learner在硬件加速器上使用来自多个Actor的成批数据来集中执行推理。
通过两种最先进的算法V-trace和R2D2,Learner可以扩展到几千个核心上,Actor的数量可以扩展到几千台机器,从而实现每秒百万帧的训练速度。
看一下实验效果:
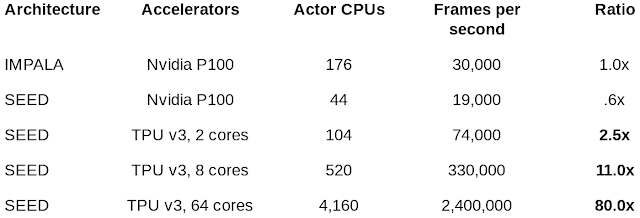
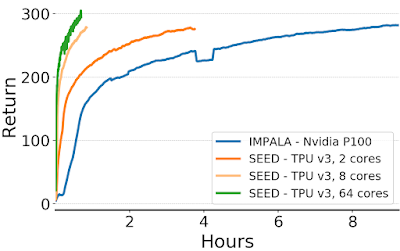

同行评审
在ICLR 2020的Official Blind Review #5给了8分。评审认为本文提出了一个在真正大规模架构上的可扩展Deep-RL框架,该框架解决了在许多Actor和Learner都在运行的情况下对此类系统进行多机培训的一些问题,介绍了IMPALA上的大规模实验和改进,从而获得了新的SOTA结果。终审认为这个架构对整个RL社区做出了重要贡献。
- 工程可靠:从工程角度来看,这项工作是可靠的。它有效地解决了现有体系结构中的问题,随附的源代码清晰且结构良好。
- 显著提速:在从ALE到DeepMindLab和GoogleResearch Football的各种基准测试中,文章提出的架构均显示出良好的性能,显示了良好的可伸缩性,并且显着减少了培训时间。
- 体系架构更改合理:从IMPALA到SEED的体系结构更改是合理的,并且结果以积极的方式支持了这些选择。与IMPALA(最新的分布式RL框架)中的分布式方法相比,该方法可重构Actor(环境)和Learner之间的接口/功能划分。最重要的是,该模型虽然在IMPALA中分配,它仅在SEED中的Learner中。提议的框架特别适合于训练大型模型,因为模型参数不会在Actor和Learner之间传递。
- 开源代码:SEED的代码是开源的,支持将来基于SEED的扩展性研究。
- 更便宜:作者由估算表明,他们提出的框架在云平台上运行更便宜。
人工智能吹响了智能大航海时代的号角,AI也成为抗疫救灾的技术主题词。新智元特推出“AI方舟”直播公开课,依托“AI开放创新平台”小程序,邀请一线AI技术专家分享实战经验,带你一起驶向载满干货的新航程。
