 恋习Python
恋习Python





数据透视表是数据分析工作中经常会用到的一种工具。Excel本身具有强大的透视表功能,Python中pandas也有透视表的实现。本文使用两个工具对同一数据源进行相同的处理,旨在通过对比的方式,帮助读者加深对数据透视表的理解。
数据源简介:
本文数据源来自网络,很多介绍pandas的文章都使用了该数据。这是一份销售数据,数据样例如下:
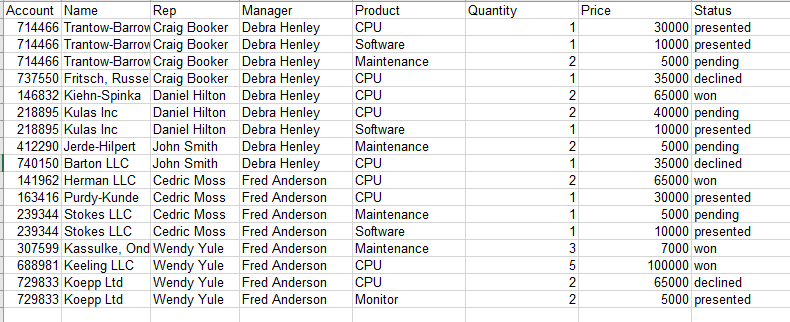
在分析之前,需要确保你安装了pandas(最好使用jupyter)和Excel(2016版)。接下来每一个环节,我们都将使用二者实现同样的效果。Python代码的部分,我都做了详细的注释,Excel操作流程我也做了比较详细的说明。后台回复“透视表”可以获得数据和代码。
处理过程
目标1:读取数据,查看数据样例
1.pandas实现
#导入必要的包
import pandas as pd
import numpy as np
#读取Excel格式的数据
df = pd.read_excel('salesfunnel.xlsx')
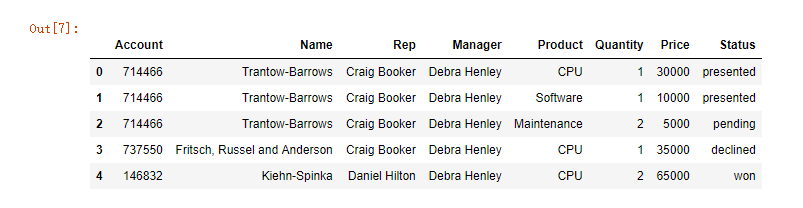
#查看数据的前5行,如果要查看多行,可以用df.head(num),num为行数
df.head()
运行效果如下:
2.excel实现
直接打开文件即可查看数据。
目标2:使用行索引,查看每一个Name的Quality,price汇总数据
1.pandas实现
pd.pivot_table(df, index=['Name'])
运行结果:
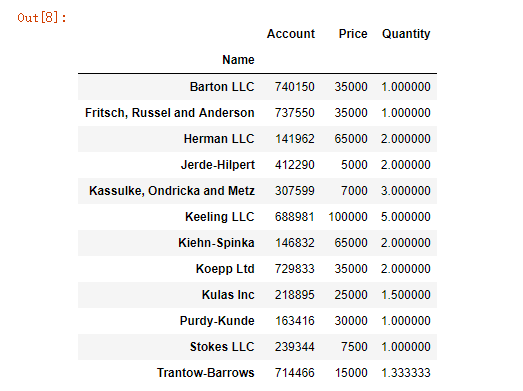
当我们只指定index时,就是指定了行标签,pivot_table函数会默认按照平均值,汇总所有的数值字段。由于Account字段被pandas“理解”成了数值类型的(可以通过df.dtypes查看),所以结果中出现了Account列。上面的结果表示每个Name的Account,Price,Quantity的平均值。
2.Excel实现
选中数据区域,插入,数据透视表,将Name字段拉倒“行”区域,Account,Price,Quantity拉入“值”区域,并将三者的字段汇总方式设置为平均值。整个步骤的流程及运行结果如下图所示:
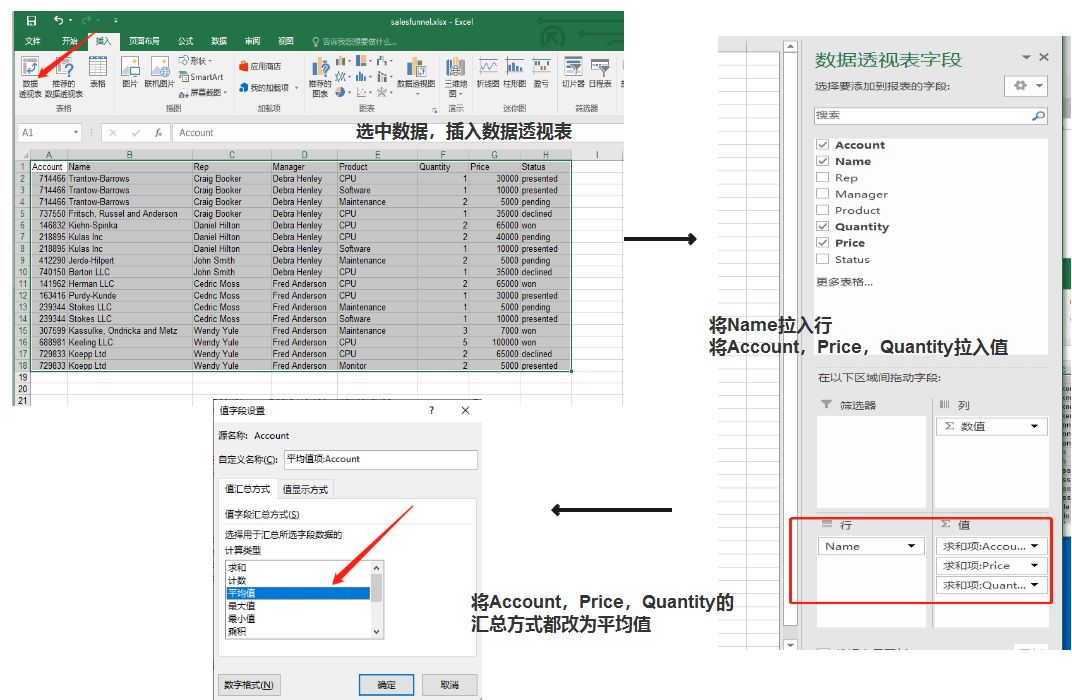
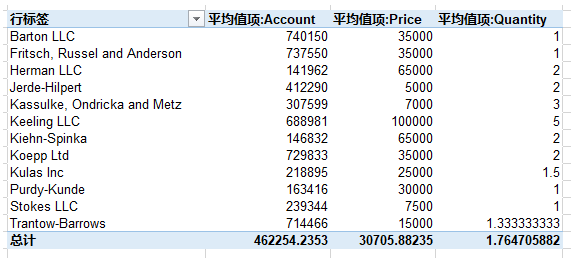
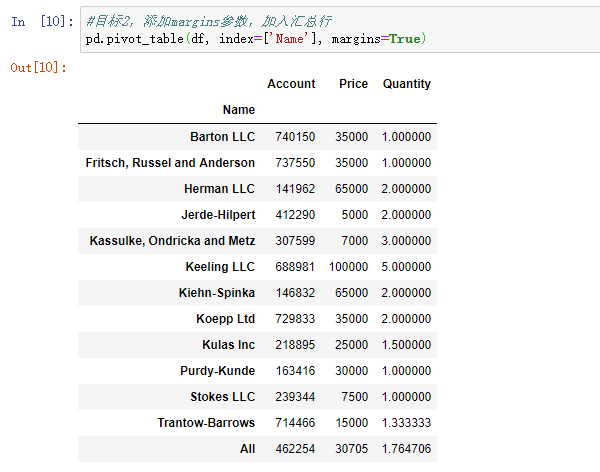
可以看到Excel默认会有一个汇总行。以Quantity为例,它的“总计”值是所有的Quantity求和之后,除以Name的个数。如果想用Pandas实现这种效果,可以加入margins=True参数,效果如下,出现了All行,由于Account和Price是整数,所以all行也是整数,Quantity是小数,相应的All行也是小数。Excel的总计行也可以在“设计”选项卡,“总计”,“对行和列禁用去掉”。
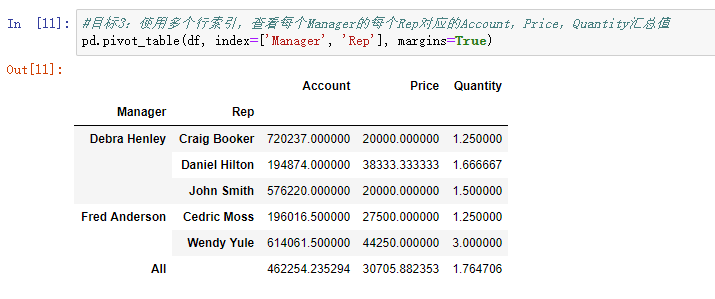
目标3:使用多个行索引,查看每个Manager的每个Rep对应的Account,Price,Quantity汇总值
1.pandas实现
pd.pivot_table(df, index=['Manager', 'Rep'], margins=True)
运行效果如下:
2.Excel实现
在前面基础上,将Manager,Rep拉到“行”的位置即可。效果如下图,可以看到,在关键的数值上,两个结果是一致的,只是在形式上有所不同。
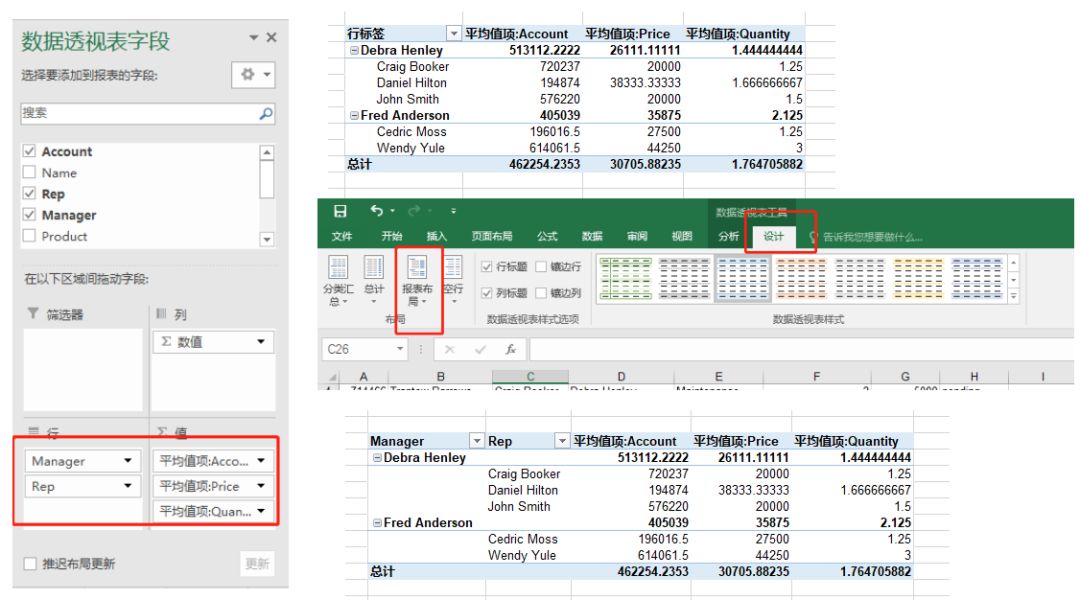
为了在形式上更接近pandas的结果,可以设置透视表的布局。选择“设计”选项卡,报表布局,选择“大纲形式显示”即可,效果如上图所示。
仔细观察,发现excel里对每一个Manager都做了汇总。这个可以通过“设计”选项卡,“分类汇总”,“不显示分类汇总”去掉。pandas如何实现分类汇总,这个暂时还没有找到相关资料。
目标4:设置我们关心的汇总字段,此处设置price,去掉Account和Quantity
1.pandas实现
pd.pivot_table(df, index=['Manager', 'Rep'], values=['price], margins=True)
结果如下图左侧所示:
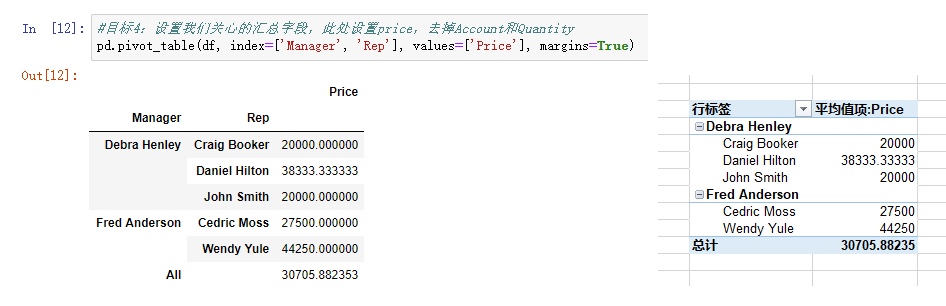
2.Excel实现
Excel中只需要在上面的基础上,在“值”的地方删掉Account,Quality即可。效果如上图右侧图所示。
目标5:实现对Price的求和
1.Pandas实现
pd.pivot_table(df, index=['Manager', 'Rep'], values=['Price'], aggfunc=np.sum, margins=True)
效果如下图左图所示:
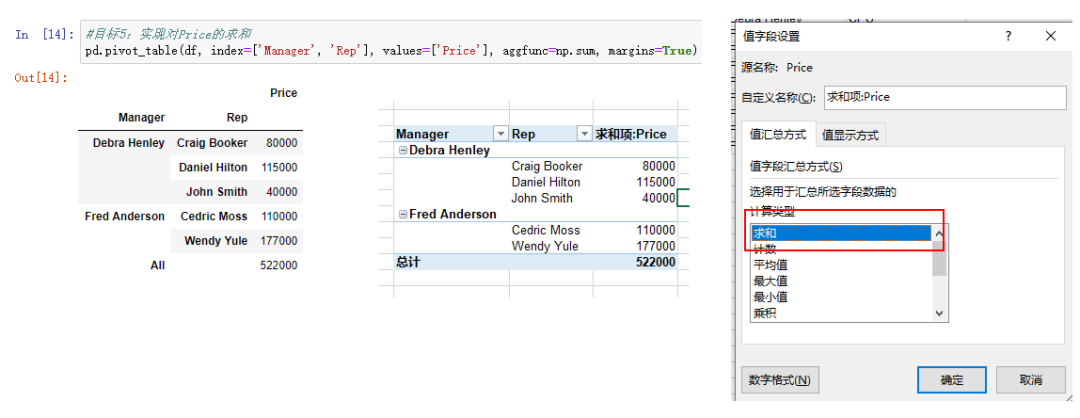
2.Excel实现
需要在上一步的基础上,将Price的值字段设置改成求和即可,如上图右图中图所示。结果如上图中间所示。
注:Pandas可以同时对一个字段进行多种汇总操作,(Excel貌似不行)
pd.pivot_table(df, index=['Manager', 'Rep'], values=['Price'], aggfunc=[np.sum, np.size] margins=True)#np.size可以换成len,效果一致
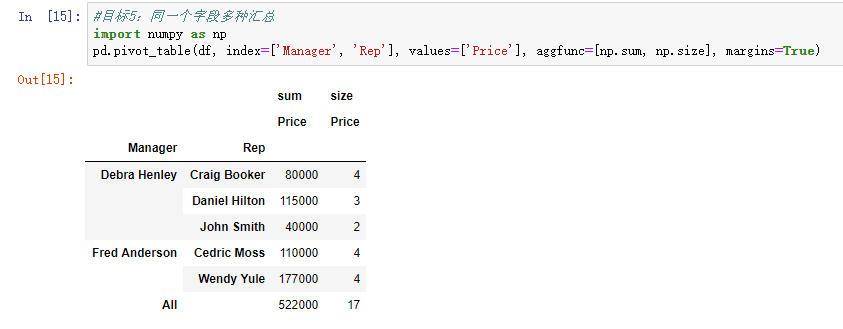
目标6: 使用列索引,查看不同产品的数据情况
1、pandas实现
pd.pivot_table(df, index=['Manager', 'Rep'], columns=['Product'], values=['Price'], aggfunc=np.sum, margins=True)
结果如下图所示:
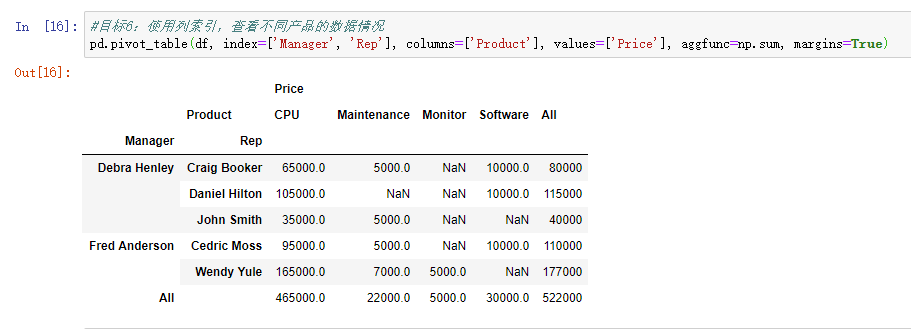
2.Excel实现
在上面的基础上,将Product拉到“列”的位置即可。
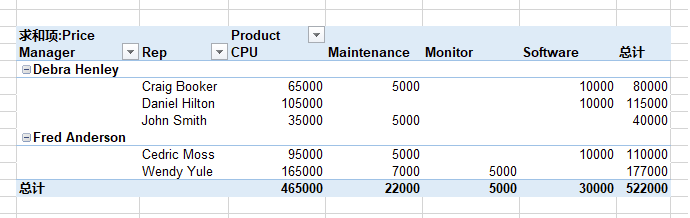
可以看到,有些位置没有对应的值,Pandas默认用NaN填充,Excel则采用置空处理。Pandas可以增加fill_value参数设置为0。(Excel貌似不可以设置)
pd.pivot_table(df, index=['Manager', 'Rep'], columns=['Product'], values=['Price'], aggfunc=np.sum, margins=True, fill_value=0)
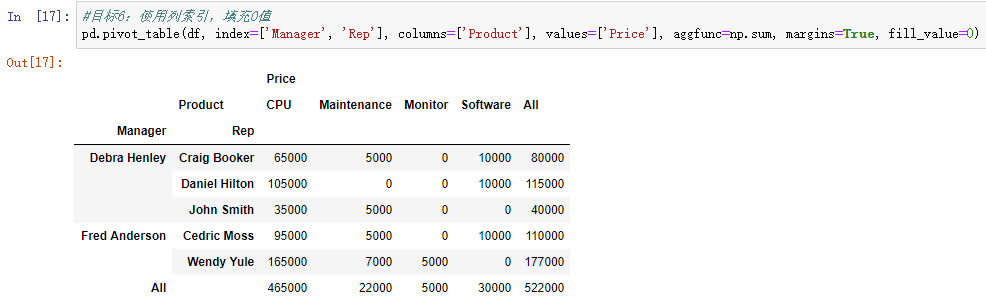
目标7:使用行索引和列索引,同时查看多个字段(Price,Quality)的汇总值
1.Pandas实现
pd.pivot_table(df, index=['Manager', 'Rep'], columns=['Product'], values=['Price', 'Quantity'], aggfunc=np.sum, margins=True, fill_value=0)
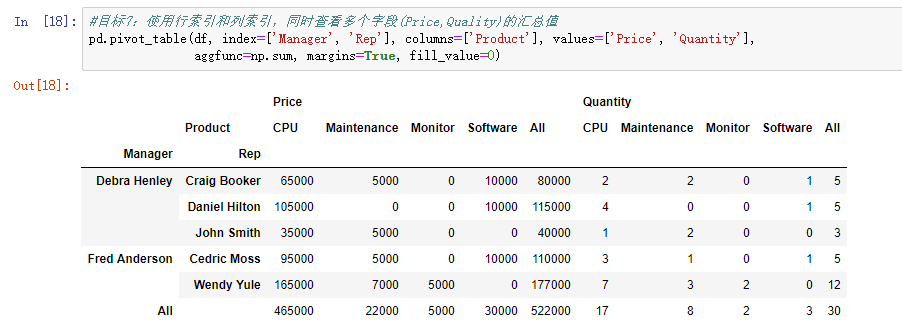
2.Excel实现
在上面的基础上,只需在“值”的位置加入Quantity,并将值字段设置为“求和”即可。值得一提的是,可以通过“列”的位置,“数值”和“Product”的上下关系,控制显示的格式,下面显示的结果和pandas的结果一致,读者可以调整下看看效果。

目标8:行列索引的转换,把Product由列索引改为行索引
1.pandas实现
pd.pivot_table(df, index=['Manager', 'Rep', 'Product'], values=['Price', 'Quantity'], aggfunc=np.sum, margins=True, fill_value=0)
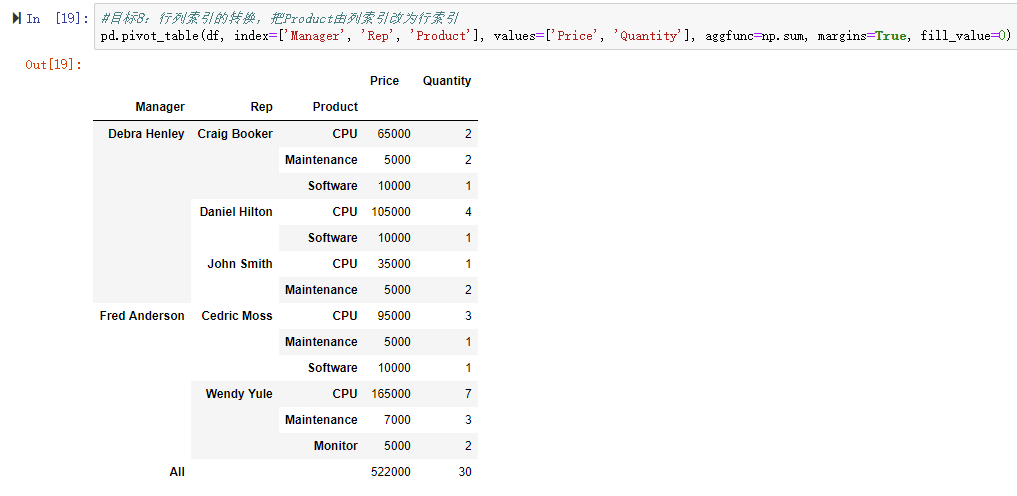
2.Excel实现
在上一步的基础上,将Product从“列”位置拖到“行”位置即可。
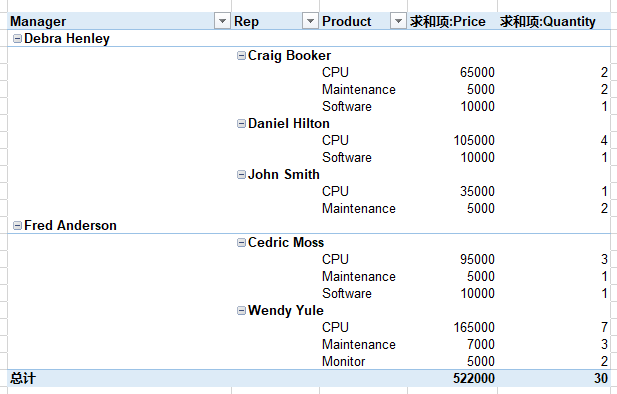
目标9:对Price和Quantity使用不同的汇总方式
1.pandas实现
通过字典的方式,为不同的字段传入不同的聚合函数。
pd.pivot_table(df, index=['Manager', 'Rep'], columns=['Product'], values=['Price', 'Quantity'], aggfunc={'Price': np.sum, 'Quantity': np.size}, margins=True, fill_value=0)
2.Excel 实现
只需在目标7的基础上,将Price和Quantity的值字段设置成相应的聚合方式即可。如下图所示。

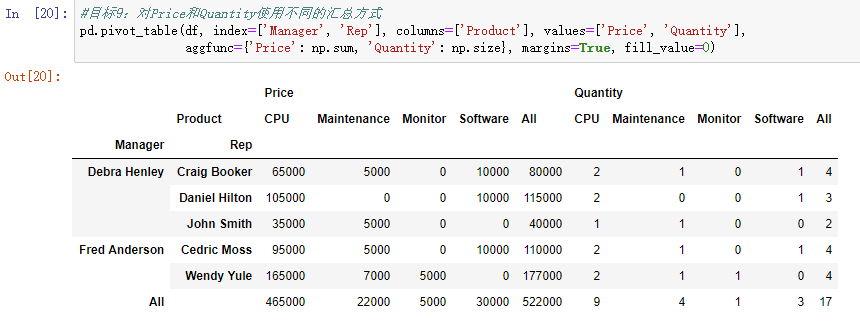
注:同一个字段可以用列表方式传多个函数。
pd.pivot_table(df, index=['Manager', 'Rep'], columns=['Product'], values=['Quantity', 'Price'], aggfunc={'Quantity':np.size, 'Price': [np.sum, np.mean] }, fill_value=0)
目标10:实现透视表筛选功能,只查看Debra Henley的数据
1.pandas实现
table = pd.pivot_table(df, index=['Manager', 'Rep'], columns=['Product'], values=['Price', 'Quantity'], aggfunc={'Price': np.sum, 'Quantity': np.size}, margins=True, fill_value=0)
table.query('Manager == ["Debra Henley"]')
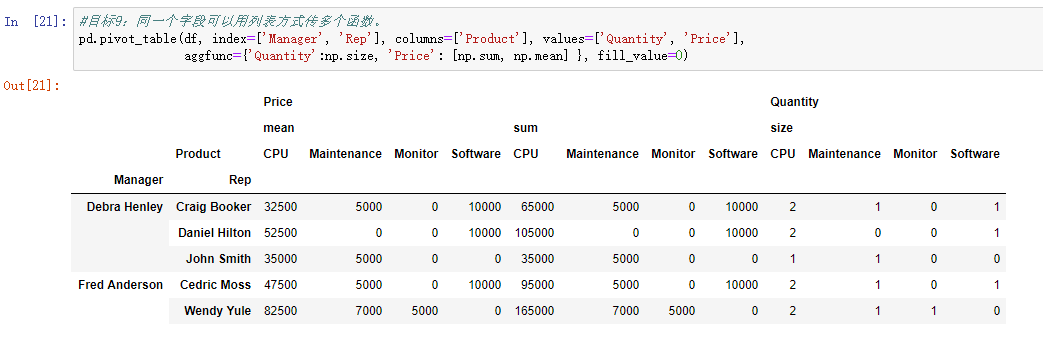
使用query传入筛选的参数即可,列表里可以传入多个参数,如 table.query('Rep == ["Craig Booker", "John Smith"]')
2.excel实现
做好的数据透视表,具有行和列的筛选功能。我们在9的基础上,对manager进行筛选,保留Debra Henley即可。效果如下所示:
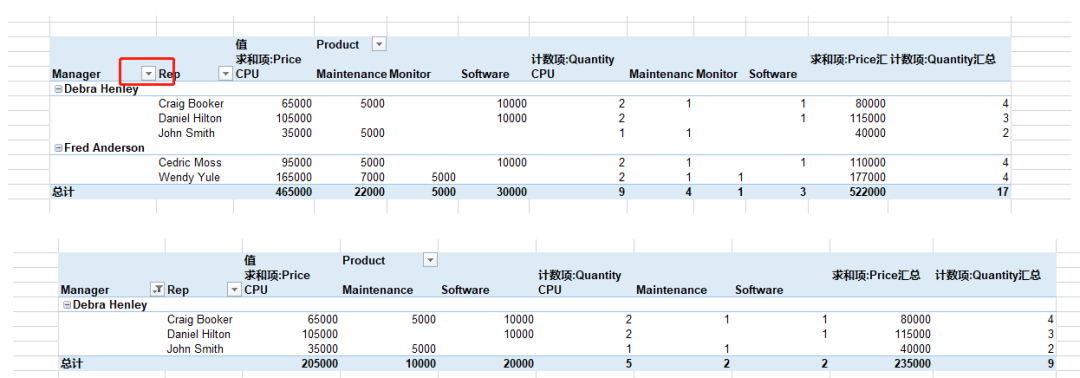
也可以将manager字段拉到“筛选器”的位置来实现,再选择Manager的值为Debra Henley即可。

小结与备忘
index-对应透视表的“行”,columns对应透视表的列,values对应透视表的‘值’,aggfunc对应值的汇总方式。用图形表示如下:
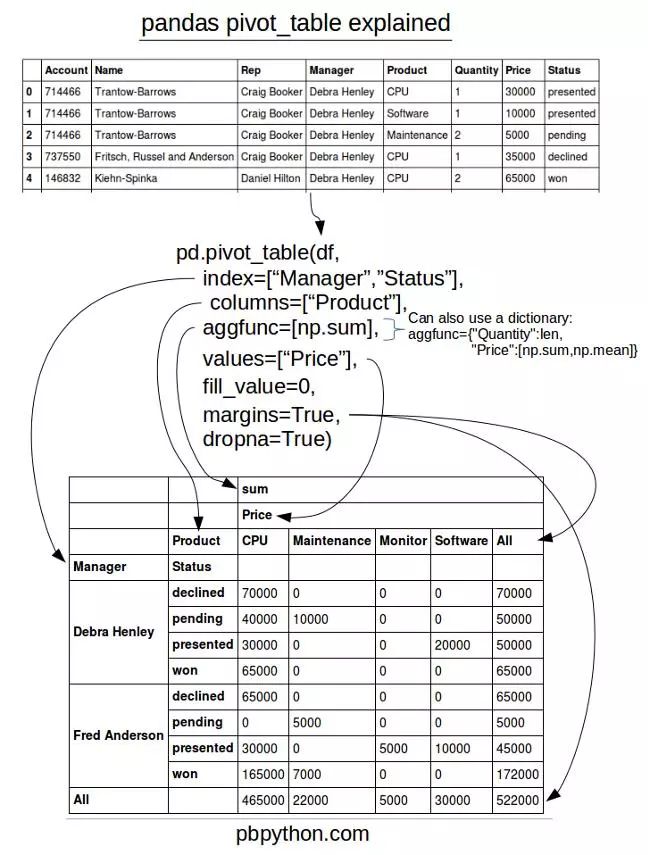
后台回复“透视表”,可获得本文代码与数据。
觉得不错,记得点个在看哦!
