
专科生阿里大数据一面面经「已过」「附详细答案」
漫画编程
共 3795字,需浏览 8分钟
· 2019-08-24
这篇文章是我学习群里一个小兄弟的面试总结,他是专科大三,很早之前找我指导了学习路线,学习很认真努力,目前他已经过了阿里一面。
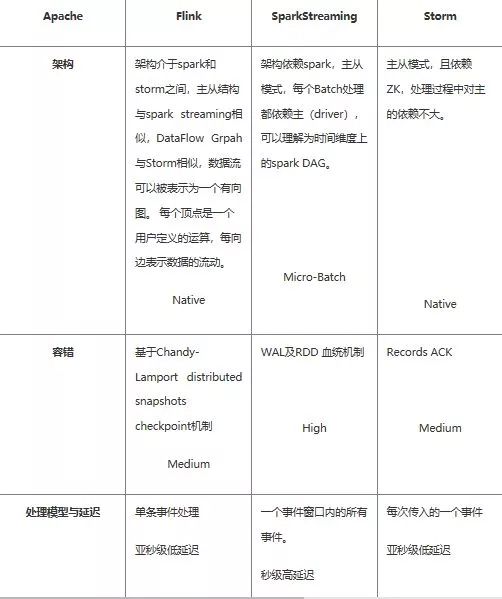
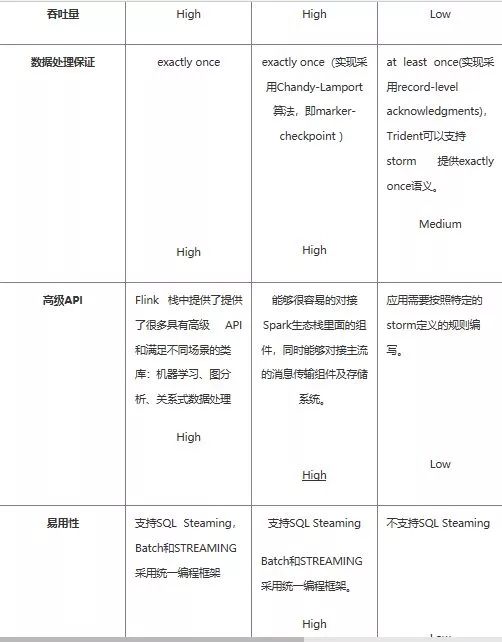
这部分由于内容太多,只提供部分重点答案。
spark shuffle:因为具有某种共同的特征的一类数据需要最终汇聚 (aggregate)到一个计算节点进行计算 ,这个数据重新打乱然后汇聚到不同节点的过程就是 shuffle。
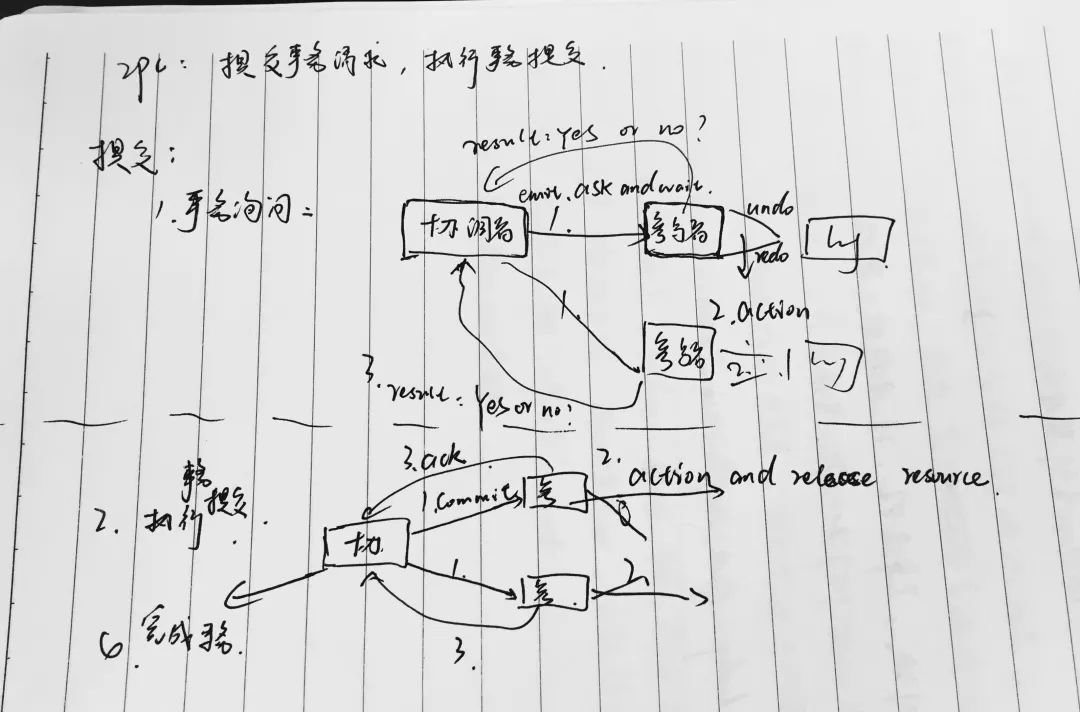 两阶段提交分为两个阶段,第一阶段是提交事务请求,第二阶段是执行事务提交。首先是提交事务请求,它分为三小步:1.首先就是事务询问,协调者向参与者发送事务内容,询问是否可以执行事务提交操作,并开始等待各参与者响应。2.然后就是执行事务,各参与者节点执行事务操作,并将undo和redo信息计入事务日志中。3.最后就是各参与者向协调者反馈事务询问的响应,如果参与者成功执行了事务操作,那么就反馈反馈给协调者YES响应,表示事务可以执行;如果参与者没有成功执行事务,那么反馈给协调者NO响应,表示事务不可以执行。如果所有参与者都响应YES,那么就开始第二阶段
两阶段提交分为两个阶段,第一阶段是提交事务请求,第二阶段是执行事务提交。首先是提交事务请求,它分为三小步:1.首先就是事务询问,协调者向参与者发送事务内容,询问是否可以执行事务提交操作,并开始等待各参与者响应。2.然后就是执行事务,各参与者节点执行事务操作,并将undo和redo信息计入事务日志中。3.最后就是各参与者向协调者反馈事务询问的响应,如果参与者成功执行了事务操作,那么就反馈反馈给协调者YES响应,表示事务可以执行;如果参与者没有成功执行事务,那么反馈给协调者NO响应,表示事务不可以执行。如果所有参与者都响应YES,那么就开始第二阶段1.首先由协调者向所有参与者节点发出commit请求。
2.参与者接收到commit请求后,会正式执行事务提交操作,并在完成提交后释放在整个事务执行期间占用的事务资源。
3.然后参与者在完成事务提交之后,向协调者发送确认ack消息。
4.协调者接收到所有参与者反馈的ack消息后,完成事务。
优点是:原理简单,实现方便。缺点:同步阻塞,单点问题,脑裂,太过保守。3PC: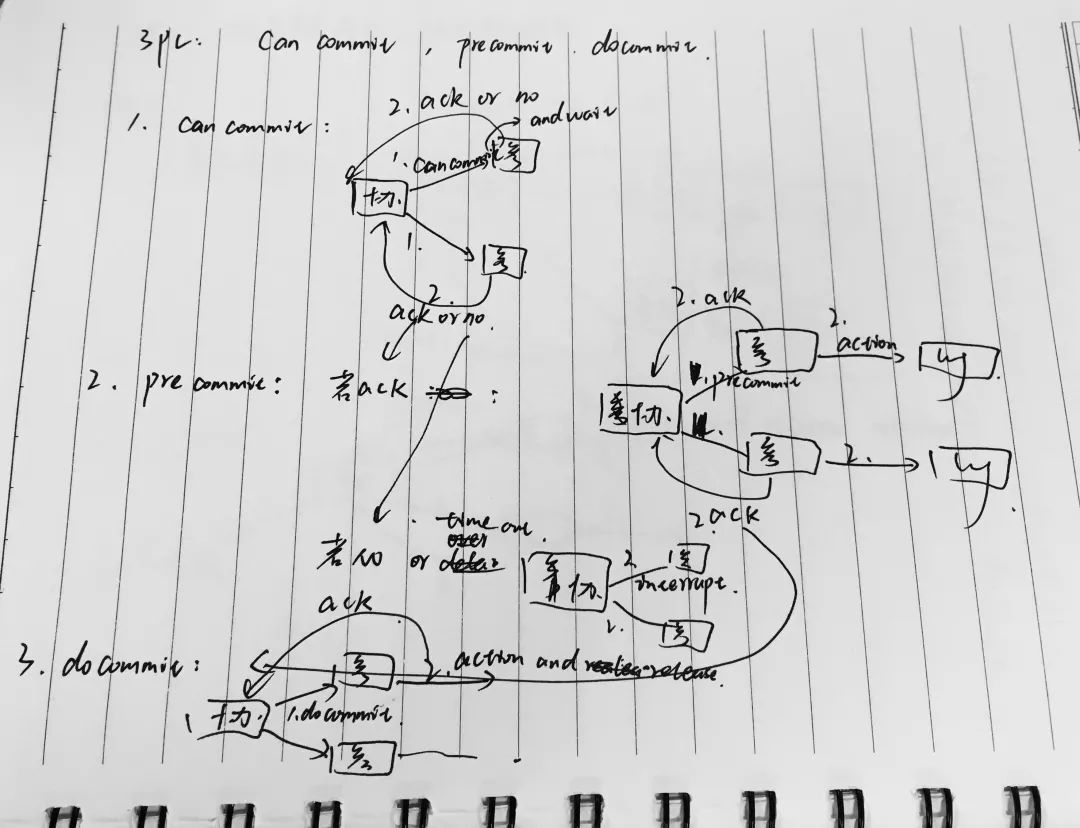 三阶段提交分为三个阶段,分别是cancommit, precommit, docommit.1.首先是cancommit阶段,协调者向所有参与者发送事务内容在内的cancommit请求。并等待参与者的反馈。2.参与者收到cancommit请求后,若判断自己可以顺利执行事务,则向协调者发送ack响应,否则反馈NO相应。3.然后就是precommit阶段,若协调者收到了所有参与者的ACK响应,则向所有的参与者发送precommit请求。4.参与者收到后执行事务,并将操作写入本地事务日志中,成功后向协调者发送ACK响应。若协调者在第一阶段的反馈中有NO,或者协调者等待超时,则向所有的参与者发送中断请求。5最后是docommit,如果协调者收到第二阶段的所有参与者的ack请求,则向参与者发送docommit请求,执行事务的提交。参与者收到docommit请求后执行事务的提交,成功后释放事务资源,并向协调者发送ACK反馈。协调者收到所有的参与者反馈后,完成事务的提交。若协调者等待超时,或者第二阶段中有参与者发送NO反馈,则向所有参与者发送中断请求。参与者收到后执行事务回滚,回滚结束后释放事务资源。参与者向协调发送ACK响应,协调者收到所有的ACK响应后中断事务。缺点:单点故障,数据不一致。优点:解决了同步阻塞问题(超时提交策略,第三阶段参与者等待超时后会提交事务)。由于precommit解决同步阻塞的问题。Paxos:
三阶段提交分为三个阶段,分别是cancommit, precommit, docommit.1.首先是cancommit阶段,协调者向所有参与者发送事务内容在内的cancommit请求。并等待参与者的反馈。2.参与者收到cancommit请求后,若判断自己可以顺利执行事务,则向协调者发送ack响应,否则反馈NO相应。3.然后就是precommit阶段,若协调者收到了所有参与者的ACK响应,则向所有的参与者发送precommit请求。4.参与者收到后执行事务,并将操作写入本地事务日志中,成功后向协调者发送ACK响应。若协调者在第一阶段的反馈中有NO,或者协调者等待超时,则向所有的参与者发送中断请求。5最后是docommit,如果协调者收到第二阶段的所有参与者的ack请求,则向参与者发送docommit请求,执行事务的提交。参与者收到docommit请求后执行事务的提交,成功后释放事务资源,并向协调者发送ACK反馈。协调者收到所有的参与者反馈后,完成事务的提交。若协调者等待超时,或者第二阶段中有参与者发送NO反馈,则向所有参与者发送中断请求。参与者收到后执行事务回滚,回滚结束后释放事务资源。参与者向协调发送ACK响应,协调者收到所有的ACK响应后中断事务。缺点:单点故障,数据不一致。优点:解决了同步阻塞问题(超时提交策略,第三阶段参与者等待超时后会提交事务)。由于precommit解决同步阻塞的问题。Paxos: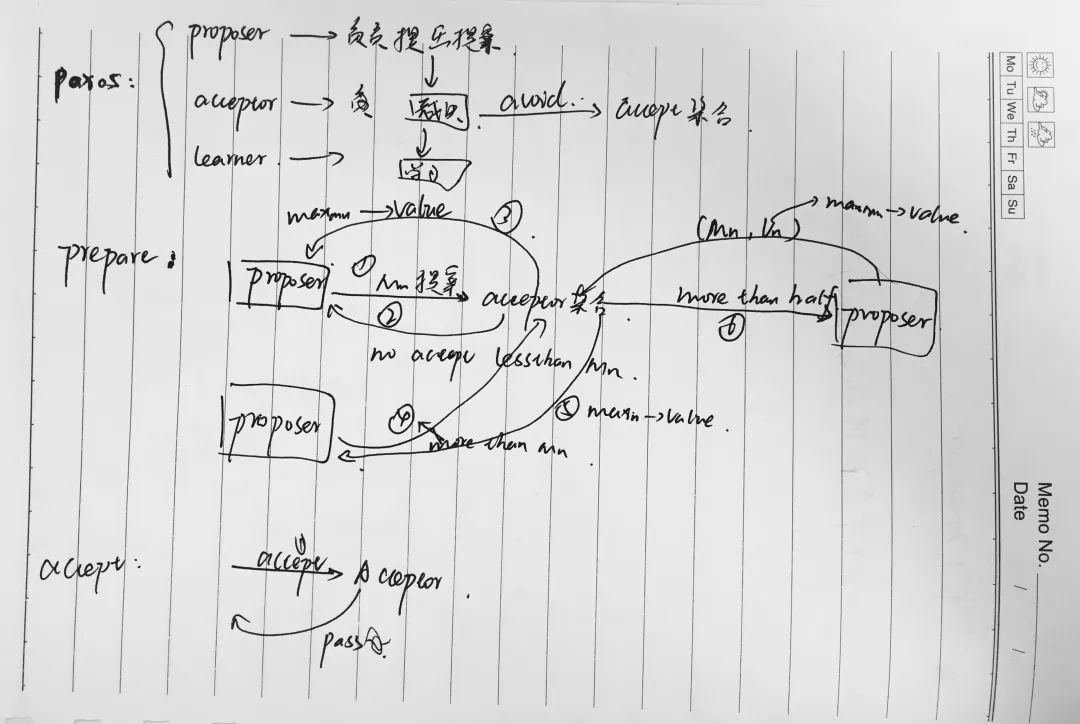 paxos算法是一种基于消息传递的且具有高度容错性的一种算法,解决的问题是一个分布式系统如何就某个值或者某个协议达成一致,该算法的前提是假设不存在拜占庭将军问题。在该算法中一共有三种角色:proposer, accpetor和learner。proposer负责提出提案,acceptor负责对该提案做出裁决,learner负责学习得到的提案。为了避免单点故障,会有一个acceptor集合,proposer向该集合发送提案,acceptor集合中的每个成员都有可能同意该提案且每个acceptor只能批准一个提案,当有一半以上的成员同意,则同意该提案。它主要分为两个阶段:分别是prepare阶段和accept阶段。首先是prepare阶段,先由proposer提出编号为Mn的提案,向accpetor集合发送prepare请求。Accept做出反馈:保证不会再接受编号比Mn小的提案;如果acceptor已经批准过某提案,会向proposer返回已经批准的编号最大的提案的value值。如果acceptor收到一个编号为Mn的请求且编号大于accpetor已经响应的所有prepare请求的编号,则它会将自己已经批准过的编号最大的提案值反馈给proposer,同时acceptor承诺不会再接受编号比Mn小的提案。(优化:忽略编号小于已批准的提案的请求)。如果proposer收到了集合至少一半的响应,则会发送一个针对Mn Vn的accept请求给Accpetor。Vn为收到的所有响应中编号最大的提案的值。如果响应不包括值,则可以由proposer选择任意值。然后就是accpet阶段,accpet阶段是接受提案的要求。当Acceptor收到accpet请求后,只要未收到任何编号大于Mn的prepare请求,则通过该提案。优化:为了避免死循环,比如两个proposer一次提出一系列编号递增的提案,可以产生一个主proposer,提案只能由主proposer负责提出。paxos算法的应用:chubby(分布式锁服务、GFS中master选举)。六、说说一致性哈希算法?
paxos算法是一种基于消息传递的且具有高度容错性的一种算法,解决的问题是一个分布式系统如何就某个值或者某个协议达成一致,该算法的前提是假设不存在拜占庭将军问题。在该算法中一共有三种角色:proposer, accpetor和learner。proposer负责提出提案,acceptor负责对该提案做出裁决,learner负责学习得到的提案。为了避免单点故障,会有一个acceptor集合,proposer向该集合发送提案,acceptor集合中的每个成员都有可能同意该提案且每个acceptor只能批准一个提案,当有一半以上的成员同意,则同意该提案。它主要分为两个阶段:分别是prepare阶段和accept阶段。首先是prepare阶段,先由proposer提出编号为Mn的提案,向accpetor集合发送prepare请求。Accept做出反馈:保证不会再接受编号比Mn小的提案;如果acceptor已经批准过某提案,会向proposer返回已经批准的编号最大的提案的value值。如果acceptor收到一个编号为Mn的请求且编号大于accpetor已经响应的所有prepare请求的编号,则它会将自己已经批准过的编号最大的提案值反馈给proposer,同时acceptor承诺不会再接受编号比Mn小的提案。(优化:忽略编号小于已批准的提案的请求)。如果proposer收到了集合至少一半的响应,则会发送一个针对Mn Vn的accept请求给Accpetor。Vn为收到的所有响应中编号最大的提案的值。如果响应不包括值,则可以由proposer选择任意值。然后就是accpet阶段,accpet阶段是接受提案的要求。当Acceptor收到accpet请求后,只要未收到任何编号大于Mn的prepare请求,则通过该提案。优化:为了避免死循环,比如两个proposer一次提出一系列编号递增的提案,可以产生一个主proposer,提案只能由主proposer负责提出。paxos算法的应用:chubby(分布式锁服务、GFS中master选举)。六、说说一致性哈希算法?https://juejin.im/post/5ae1476ef265da0b8d419ef2
为什么会发生误判:假如此时再查询X3这个元素是否属于集合,通过3个哈希函数计算后的位置数为 2,7,11 ,而这时这3个位置都为1,BF会认为X3属于集合,这样岂不是误判了。
漏判:会发生误判但一定不会发生漏判,因为整个过程不存在将 1 改为 0的情况。
影响误判率的因素:1.集合大小 n。因为集合n越大,其它条件固定的情况下,位数组中就会有更多比例的位置被设成1,误判率就会增大。2. 哈希函数的个数k。个数越多,位数组中更多比例的位置被设置为1,即增大了 误判率。但在查询时,显然个数越多的时候误判率会越低。3. 位数组的大小 m。位数组大小 m越大,那么在 n和k固定的情况下,位数组中剩余0的比特位就越高,误判率就会减小。
已知 k,n,m 即可计算出对应的误判率。已知 n,m 最优的哈希函数个数为:k = n/m * ln2已知集合大小n,并设定好误判率 p, 问:m的大小如何确定?m = - n*lnp / (ln2)^2
缺点:无法删除集合成员,只能增加成员并对其查询。改进:计数 BF (Counting Bloom Filter)
思考:为什么基本BF无法实现删除?答:其基本信息单位是 1 个比特位。所以只能表达两种状态。计数BF 的 基本信息单元 由多个比特位组成,一般为3到4个。
使用过程:将集合成员加入 位数组时,根据k个哈希 函数进行计算,只需要将原先的数值 +1 即可。查询集合成员时,只要对应位置的信息单元都不为 0 ,即判定该成员属于集合。
删除成员:只要将对应位置的计数 -1 即可。改进的代价:位数组大小倍数增加。另外存在计数溢出的可能,因为比特位表达能力仍然有限,计数很大的时候存在计数溢出的问题。
1.父类静态变量初始化。
2.父类静态代码块。
3.子类静态变量初始化。
4.子类静态语句块。
5.父类变量初始化。
6.父类代码块。
7.父类构造函数。
8.子类变量初始化。
9.子类语句块。
10.子类构造函数。
static {
name="大数据肌肉猿";
}
private static String name=null;
上面这段代码,把name打印出来是null
-------
private static String name=null;
static {
name="大数据肌肉猿";
}
上面这段代码,把name打印出来是 大数据肌肉猿
--------
static {
name="大数据肌肉猿";
}
private static String name;
上面这段代码,把name打印出来是大数据肌肉猿由此可见,变量名首先被加载,而赋值的时候,无论是直接在变量上赋值还是在静态代码块中赋值,都是按照代码的顺序赋值的。
十、Mysql问的比较少,只问了索引的数据结构?
十一、Synchronized 与volatile 关键字的区别?
Synchronized 解决执行控制问题,它会其它线程获取当前对象的监控锁,使得当前对象中被Synchronized关键字保护的代码块无法被并发执行,并且Synchronized 还会创建一个 内存屏障,保证了所有CPU操作结果都会直接刷到主存中去,从而保证了可见性。
内存可见:控制的是线程执行结果在内存中对其它线程的可见性,根据Java内存模型的实现,Java线程在具体执行时,会先拷贝主存中的数据 到线程本地(CPU缓存),操作完成后再把结果从线程刷到主存中;
volatile 解决了内存可见,所有对volatile关键字的读写都会直接刷到主存中去,保证了变量的可见性,适用于对变量可见性有要求而对读取顺序没有要求的场景。
两者区别:1. volatile 不会造成线程的阻塞,Synchronized 会造成线程的阻塞。2. volatile仅能使用在变量级别,Synchronized 可以使用在变量,方法,类级别上。3. volatile 标记的变量不会被编译器优化,Synchronized标记的变量会被编译器优化。4. Volatile 仅能保证变量的修改可见性,不能保证原子性,而Synchronized 可以保证变量修改的可见性和原子性。5. Volatile本质告诉JVM 当前变量在寄存器(工作内存)中的值是不确定的,需要从主存中去读取 ,Synchronized则是锁定当前变量,只有当前线程可以访问该变量,其它线程不可以。
BlockingQueue接口定义了一种阻塞的FIFO queue,每一个BlockingQueue都有一个容量,让容量满时往BlockingQueue中添加数据时会造成阻塞,当容量为空时取元素操作会阻塞。
ArrayBlockingQueue实现的队列中的锁是没有分离的,即生产和消费用的是同一个锁;
这题留言区求解答!!
推荐阅读:
 喜欢我可以给我设为星标哦
喜欢我可以给我设为星标哦
好文章,我 在看

评论