
全年被女友拉黑 360+ 次?或许只有 AI 能拯救你!
共 4080字,需浏览 9分钟
· 2019-06-01

这是Han的第57篇原创文章
Hi,这里是Han。
有读者说:你太久没聊技术了。好的,今天我就硬核起来,讲讲AI技术框架吧。
不过,咱也得解决个实际问题。
我好多哥们儿经常抱怨,总惹妹子生气,然后就被拉黑,真是崩溃。
今天,咱就来开个脑洞,看看AI可以怎么拯救你吧!
本周,深度学习框架PaddlePaddle,AI框架国货之光,上新了!
在2019 Wave Summit,也是中国首个深度学习开发者峰会上,百度对旗下的PaddlePaddle框架进行了全面升级和功能发布。
先说深度学习框架,具体有什么意义呢?我觉得,对于开发者而言,最核心一点就是:省事。
你不用再重复造轮子了。比如,最基本的,你不用手写CUDA就可以在GPU上跑,也不用自己手算复杂的梯度了。
而产业发展到今天,框架更像是一个武器,AI工程师们作为战士,可以随意使用,而且力量强大,可以帮你完成从底层的硬件计算,到跨服务器并行计算等复杂操作。
说起流行的深度学习框架,因为我在硅谷,自然总是听到Caffe2, PyTorch 和 TensorFlow这些名字,而PaddlePaddle则是中国目前最成熟甚至是唯一真正意义上的深度学习框架。
PaddlePaddle的定位,一直是服务产业实践,很多框架功能的研发,都是为了切实的应用而考虑的。
在本次更新后,它的功能可算是涵盖了一个AI产品,从0到1再到n的各个阶段。按照官方说法,是涵盖了从开发、训练到部署、预测的每一个环节。
以下,就是PaddlePaddle本次公布的全景图。

那么,本次都有哪些更新呢?
我觉得,光说技术就有点就干,为了让你更能看懂,今天,我就用一个虚拟的案例,来带你了解一下吧。
01.
女友老生气?用AI来预测心情呀
相信,很多哥们都有一个困扰:“额,女朋友怎么又生气了… ”尤其是,表面看起来明明是生气了,可是嘴上却说不生气。
这就让你很苦恼。
于是,你有了一个想法,能不能创建一个AI模型,来预测女友心情呢?来看看今天会不会生气之类的。
这样一来,你就可以提前做好准备了呀。
没问题,说干就干。
咱们今天就来看看,PaddlePaddle能不能完成你的所有需求呢。
基本功能而言,PaddlePaddle提供了一套Fluid API,可以让你非常方便地,从0到1快速搭建起一个AI模型。
这里只需要三步。
首先,你需要一些数据。
因为是刚开始做嘛,你决定就用少量的几个特征,主要就是之前女友的生气历史数据。
总结起来,特征数据可能是下面这样的。

Fluid当然和其他框架一样,提供很简单的API,只要1行,你就能非常方便地,导入自定义数据集。
第二步,你需要构建这个模型的网络结构。
额,这一步可就有点难度了。
有的读者可能不知道,AI的模型,说白了,是一个神经网络的层级结构。搭建起这结构来说,还是有点复杂的,有时候甚至是一个玄学,跟老中医似的,需要很多经验的积累。
毕竟,当我第一次听到 “3*3可以拆成1*3和3*1”的时候,我是这样的:???
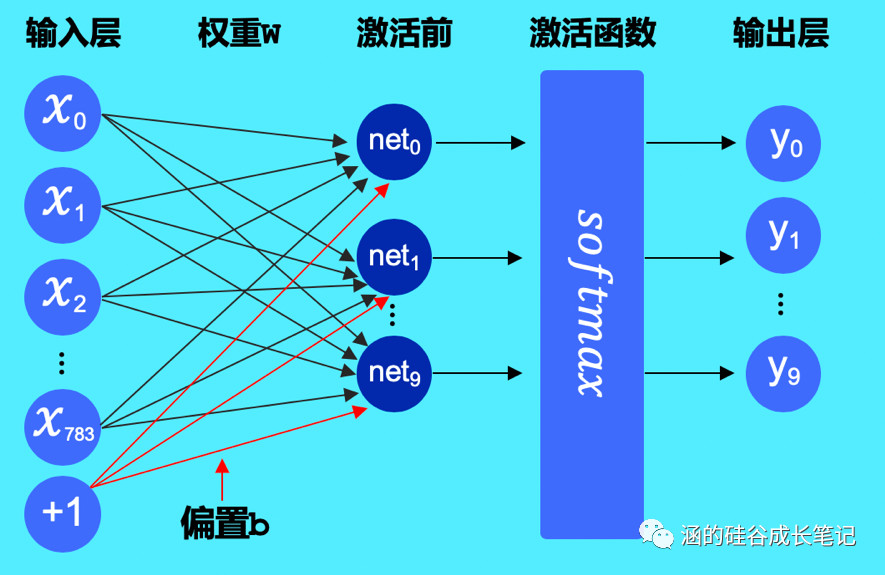
这次,PaddlePaddle居然推出了: AutoDL Design,它可以把网络结构的设计,完全自动化。
在这个系统内,它设计了两个组件:生成器和评估器。在背后,利用Reinforcement Learning,评估器就可以不断评估生成器构造出的网络结构,直到整个系统得到最优解。
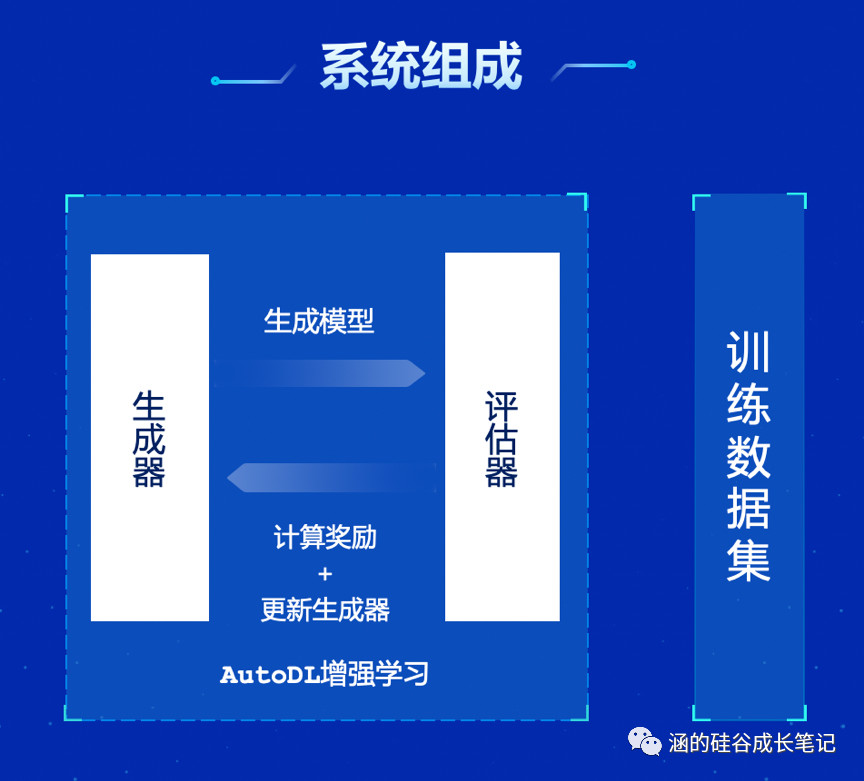
细心的你,肯定已经发现了,哦?需要用强化学习啊?那库支持吗?
没错,所以它需要配合PaddlePaddle的深度强化学习框架PARL一起使用。在本次更新中,也有更多新的算法被加入到PARL中, 比如A2C和IMPALA等等。
好了,借助AutoDL Design,第二步的模型结构设计也结束啦,那剩下的第三步,就是直接开始训练数据吧。
在自己的笔记本上跑模型,真实非常简单,只需要选择一个运算地点(CPU/GPU),然后只用一行,就可以开始训练了,像下面这样。

02.
结果不准?你需要站在巨人的肩膀上
在有了上面那个最原始的模型之后,你试了几次,发现预测并不准确啊。预测女友会生气,结果你提心吊胆了一天,结果你发现女友居然到家时超级开心。
于是,经过你的细心观察,你发现了一些蛛丝马迹。
比如,她如果穿了某件套装,并且画上了超级复杂精致的妆容,似乎今天的心情就会不错。可是,如果她没洗头,那就很有可能心情不好。
再比如,你们有时候总是微信聊着天,不知道怎么着,可能你哪句话说错了,她就发火了。
你恍然大悟,原来女朋友的妆容,还有你和女友的对话,和她发是否发火,有着很深的联系。
于是,你决定给自己的模型加入更多的复杂特征!
可是,如果要识别女友的妆容,就需要机器视觉算法,如果想要分析聊天记录,那还需要自然语言处理的技术啊!
这也太复杂了吧。
不怕,PaddlePaddle本次升级,全新提供了工业化级别的NLP更多算法模型库,并首次开源了视频相关的CV算法模型库。
NLP方面,PaddlePaddle提供的功能,不仅有基础的语义匹配、序列标注等基础能力,它更是提供了各种应用层任务,并且还都提供工业级的高质量。

比如,文本情感分析、对话模型、知识驱动对话统统支持。甚至,还支持机器翻译,这样一来,就算你的女友突然跟你说英文,模型都可以完美应对。
视觉方面,PaddlePaddle本次全新发布CV库,支持种类齐全的视频识别模型算法,无论是主流实用的序列建模算法,还是端到端的视频识别模型,都有支持。
这样来看,只要你把家里防盗摄像头的视频数据导入模型,系统瞬间就可以打上标签,比如:她今天YSL口红色号是什么,她穿的商务套装还是休闲装,她出门后3秒的表情是微笑还是皱眉,等等。

你现在可能有个疑问,提供预设的模型虽然好,可是要自己修改和使用,肯定也要费不少劲儿吧。
可不一定哦,PaddlePaddle本次还全新推出了Paddle Hub工具,让你可以用10行代码完成对于一个现成模型的迁移学习。
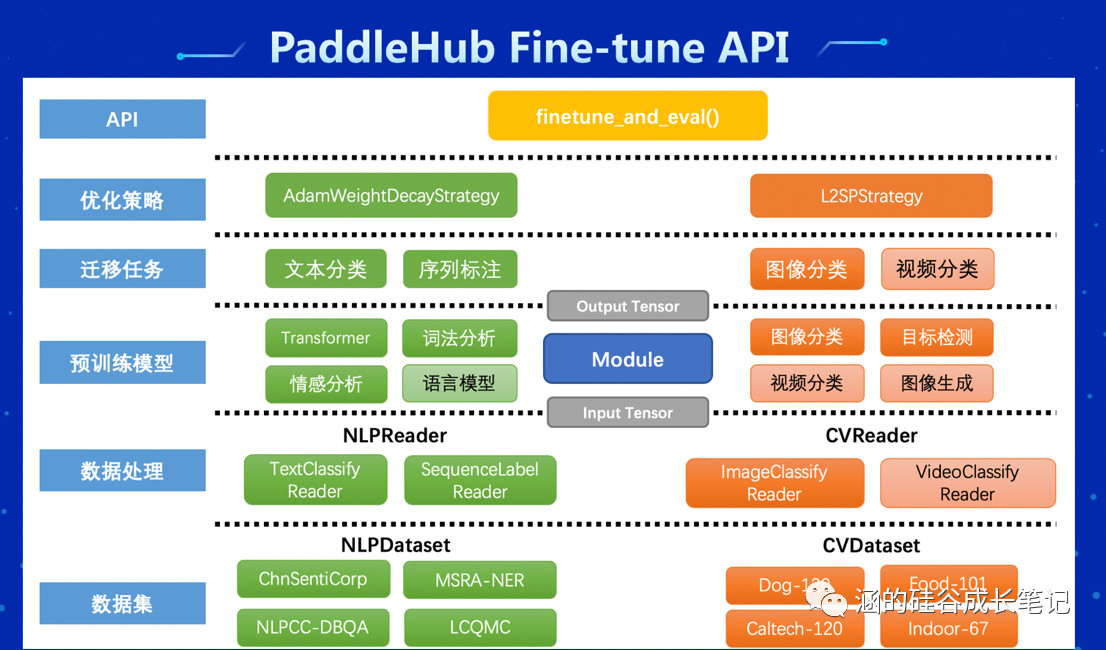
PaddleHub是一个简单好用的命令行工具,它的背后,提供有大量的工业级模型,而且可能都是万级别GPU小时得到的高质量模型呢。
站在巨人的肩膀上,你只需要再提供一些自己独特的训练数据,进行一些特定情境下的细微调整,就可以得到一个效果很不错的模型了!这就是所谓的:PaddleHub + Fine-tuning的AI应用开发模式。
03.
兄弟们也想用?App版本发布
在接入了工业级预设模型并进行了微调之后,你模型的准确度已经很好了!几乎可以准确预测女友的心情变化,简直拯救你于水火。
这个时候,你身边的兄弟们也都想使用。于是,你发现了新的机会:诶,做一个App吧!
你决定创业,制作一个移动端App,把AI模型以具体App产品的形式,发布出去。
这个时候,你开始遇到越来越多的实际问题,比如移动端和服务器端怎么连接,数据怎么回传,怎么保证服务的稳定性,等等。
以及,因为有越来越多哥们的真实数据进入,你需要不断地训练新的模型,以适应新的女友的情绪变动。
有些时候,你还需要做模型的AB在线测试,以此挑选比较好的模型,之后还要对新的模型进行热更新上线。
这真是太复杂了…
别怕,PaddlePaddle本次全新发布了Paddle Serving功能,可以完美解决上述问题。Paddle Serving具有完备的在线服务能力,并且内置成熟的服务模型支持。
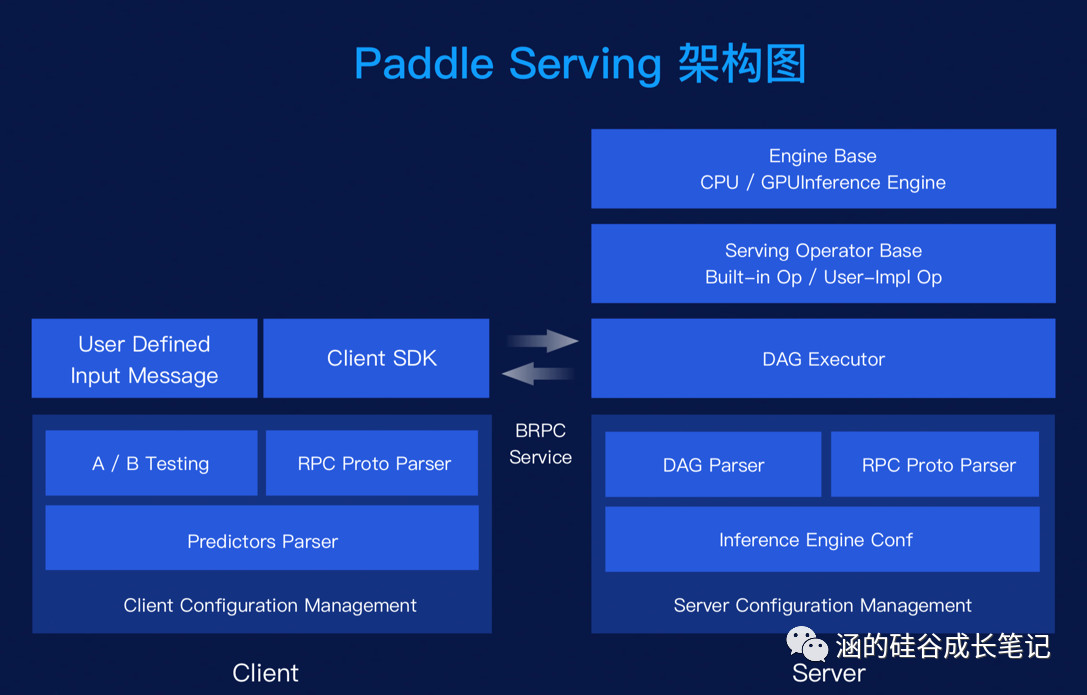
再之后,你的用户越来越多,有的用户提出需求:希望能在网络环境不好的情况下,也能使用这款App,毕竟女友的心情随时可能会变化,而且很多山区的哥们也都很需要这款产品呀。
可是,这款模型越来越大,不太适合直接发布出去了,这可怎么办。
对此,PaddlePaddle本次上线了全新模型压缩工具库PaddleSlim,并且完整支持剪枝、量化和蒸馏三大压缩策略。在保证精度几乎不变的情况下,可以让模型大小减少70%。
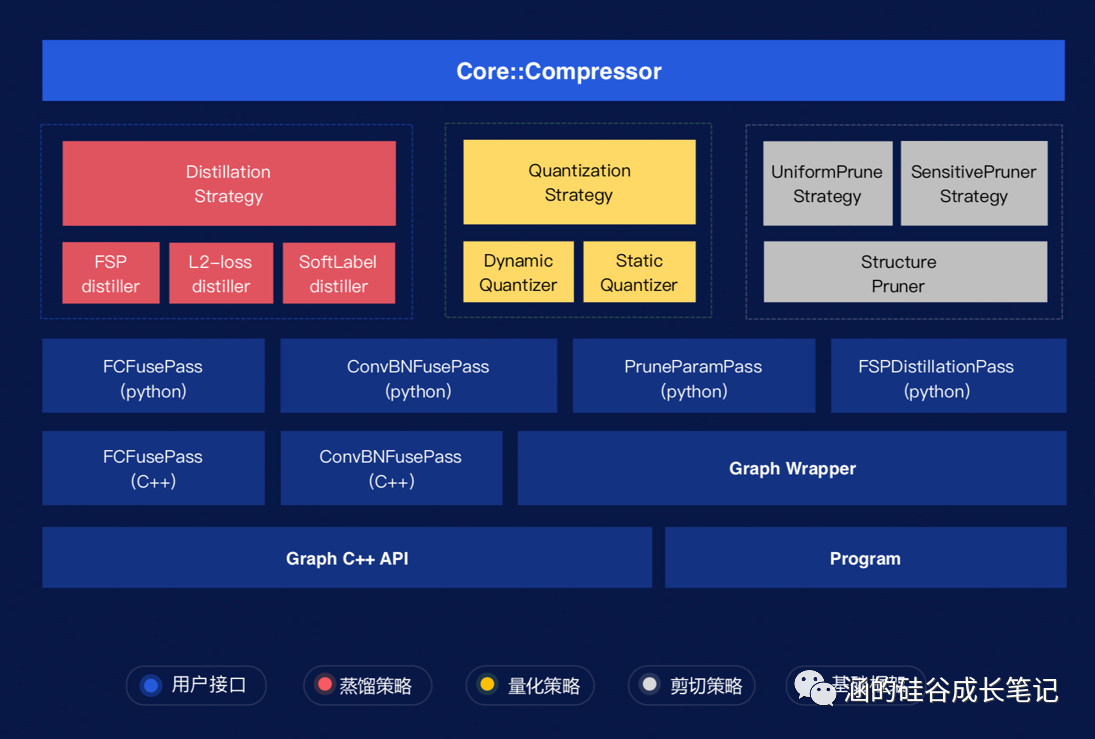
更重要的是,压缩操作完全自动,你只需要两行python代码,就可以自由调用了,非常方便。
04.
好吧,用户多到撑不住了…
你的App实在是太火了,毕竟是戳中了无数直男们的痛点,每天都有大量的新用户数据涌入,你的训练数据每天在持续不断的扩大。
而且,由于“女孩们的心思你别猜”定律,你的模型要非常快速的更新才行,否则App很可能会失去效果。
在海量数据面前,这简直就是一个天大的难题。这可怎么办?
PaddlePaddle在本次更新中,对此进行了专门的功能升级。
首先,咱们都知道一台机器速度不够,那咱们就多用几个呗。这就是所谓的分布式训练了。
PaddlePaddle本次全面升级了分布式训练功能,完全支持多机多卡,给出了解决超大规模工业级并行深度学习问题的方案。
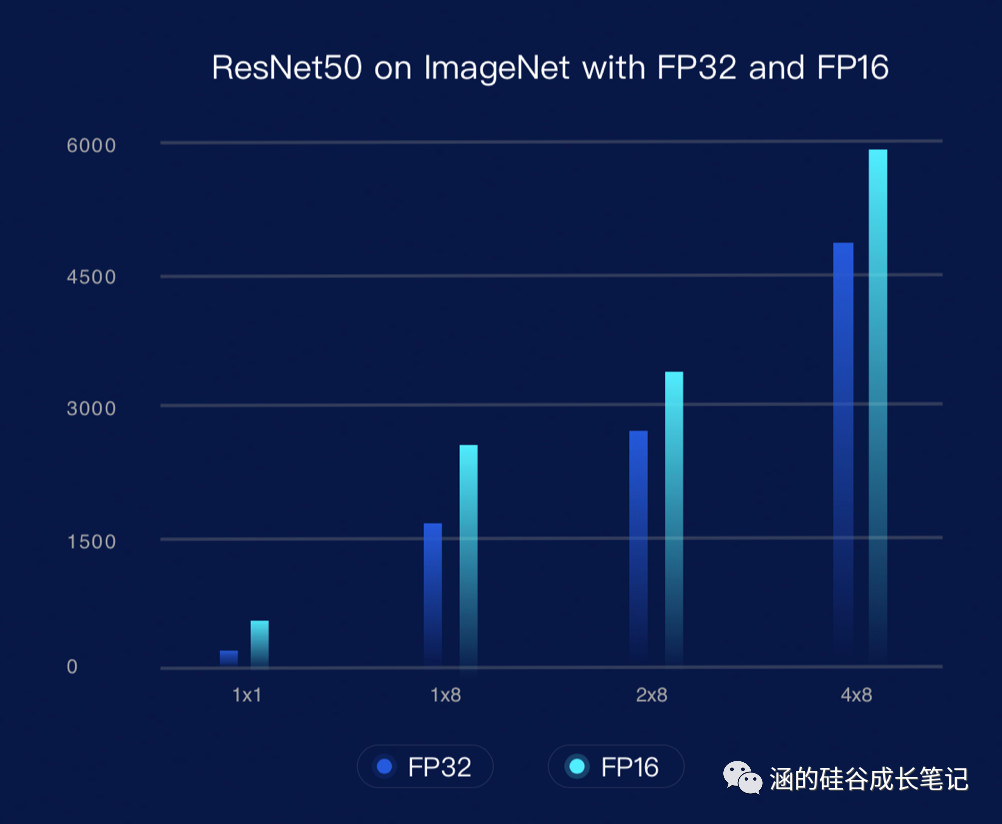
另一方面,你发现,用户提交的特征越来越多,也越来越详细,比如:“男生上一次打篮球且输了3分的时间”,“女生上一次吃火锅并且吃了冻豆腐”等等。也正是由于太详细了,很多时候这个特征只有很少的一部分用户会有。
于是,你又遇到了一个难题:大规模稀疏特征。对于此,PaddlePaddle本次全新发布大规模稀疏参数服务器,以此,系统性地解决了相关问题。
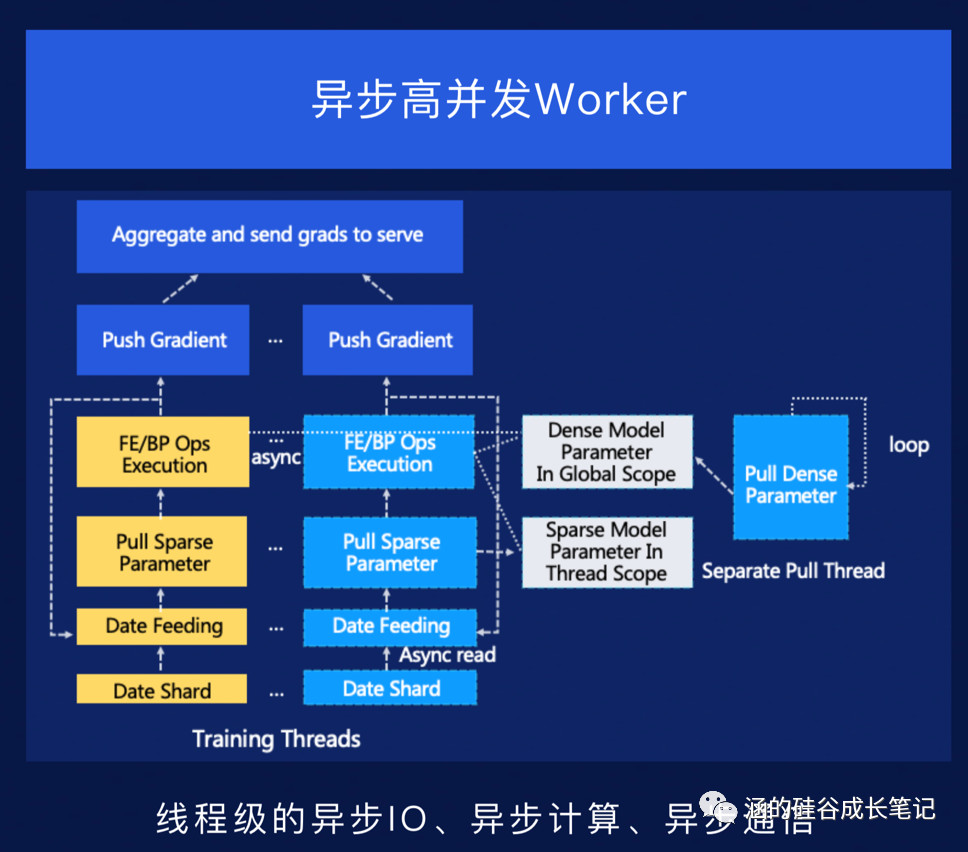
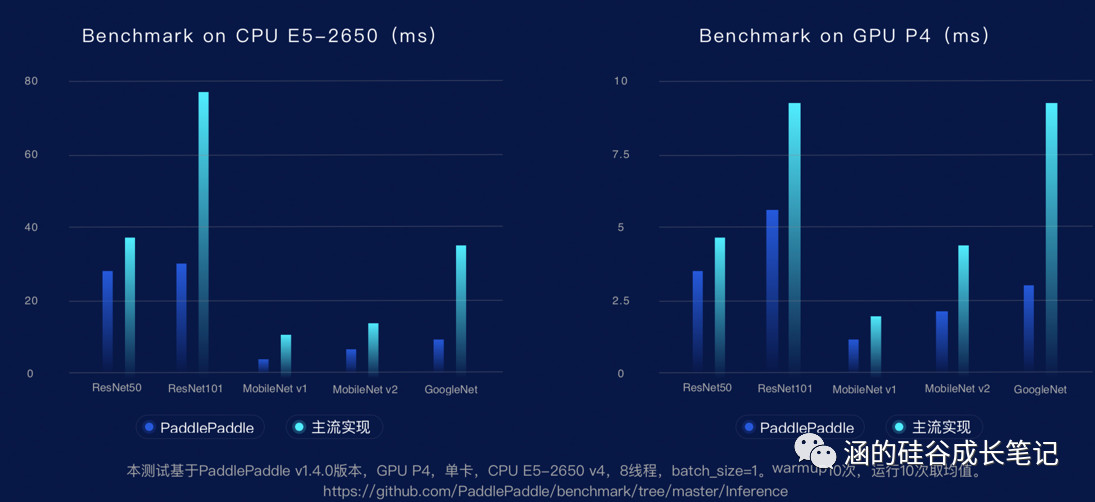
最后,推理引擎本身性能的提升,也能提高整体运算的速度。本次PaddlePaddle也同步更新了底层的高速推理引擎,推理速度大幅提升。
终
以上,我就已经把本次PaddlePaddle发布的新功能都介绍给你了。
在大会上,百度深度学习技术平台部总监马艳军说,PaddlePaddle出身于产业,超大规模数据处理能力高,场景和实际应用更贴合,更为实用。
这就是所谓的“源于产业实践的开源深度学习平台”的精神内核吧。
哦,对了。
在故事的最后,你解决了所有这些最困难的问题,你预测女友心情的App终于取得了巨大成功。
你,走上了人生巅峰…
Hey,这里是涵,一枚硅谷一线小码农。
会在这里分享:有趣干货 + 科技圈和海外有意思的事儿。