
Python处理Excel&CSV文件
共 2488字,需浏览 5分钟
· 2020-01-02
咪哥杂谈

本篇阅读时间约为 5 分钟。
1
前言
在今年很早的时候,写过一篇用 Python 玩 Excel 的文章,可以回顾《Python操作 excel ?应该这么玩!》
当时介绍了用 Pandas 库玩股票,在 Excel 中画出一个图来。
现在有了前几天爬取的王者荣耀 csv 文件,还需要用 pandas 库来操作处理下。
实战中去体会这些第三方库的使用技巧,印象才会比较深刻。
2
环境准备
开始之前,首先确保你安装了 pandas 库。
pip install pandas简单用官网介绍的文字来说明下,何为 pandas?
Pandas是一个开源的,BSD许可的库,为Python编程语言提供高性能,易于使用的数据结构和数据分析工具。
https://www.pypandas.cn/intro/
pandas中文官网
3
处理数据
一旦有了使用场景,那么,便是最好的练手机会。(再次强调)
现在我的需求很明确了:
有一个王者荣耀的 csv 数据,我需要将其读取到,然后将字典类型变成列,同时,需要让头像下载后自动写进 Excel 中。
而 Excel 的数据最终会提供给玩王者的朋友们, 也为了后续的分析而用。
1. pd.read_csv()
import pandas as pddf = pd.read_csv(path) # 读取 csv 文件,看返回的是什么?
打个断点看下,df最终返回的结果:
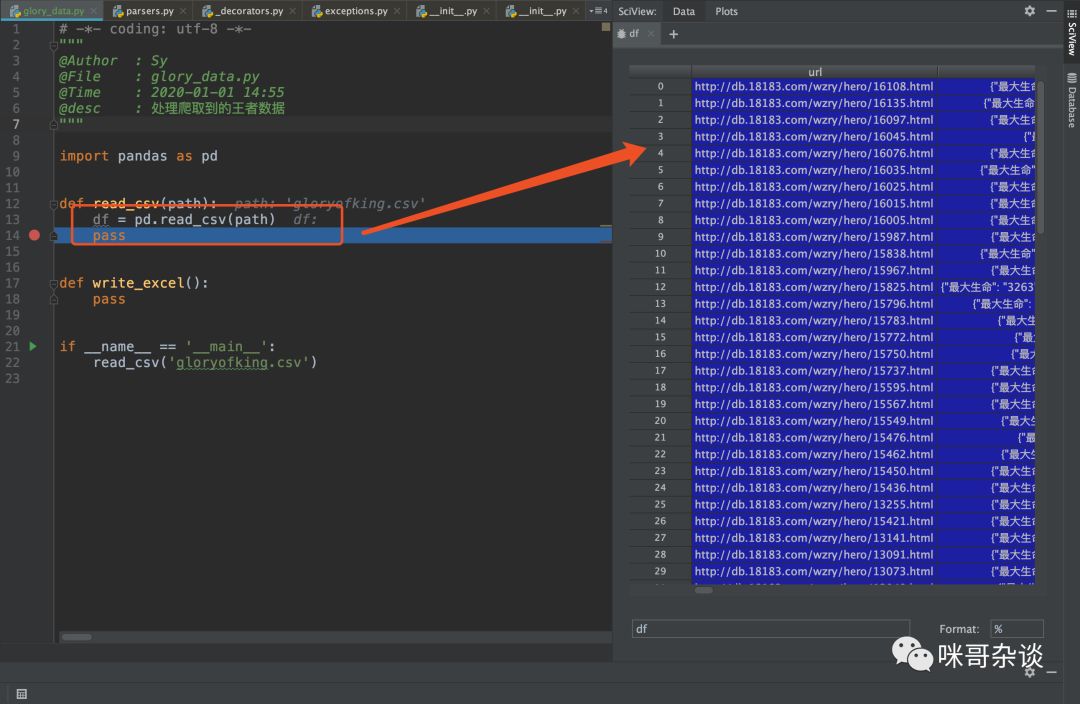
查看 debug 面板,df 的类型是 DataFrame。

来看下官网是如何介绍的?
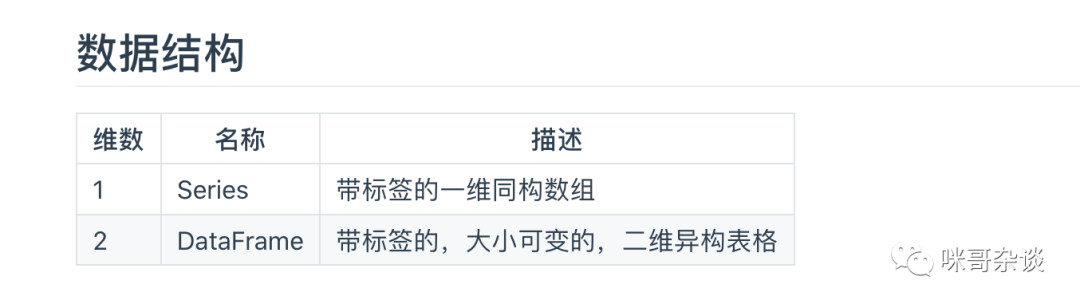
2. df['列名'] 获取单列
attr_details_data_dict = df['attr_details_data_dict'] # 获取单列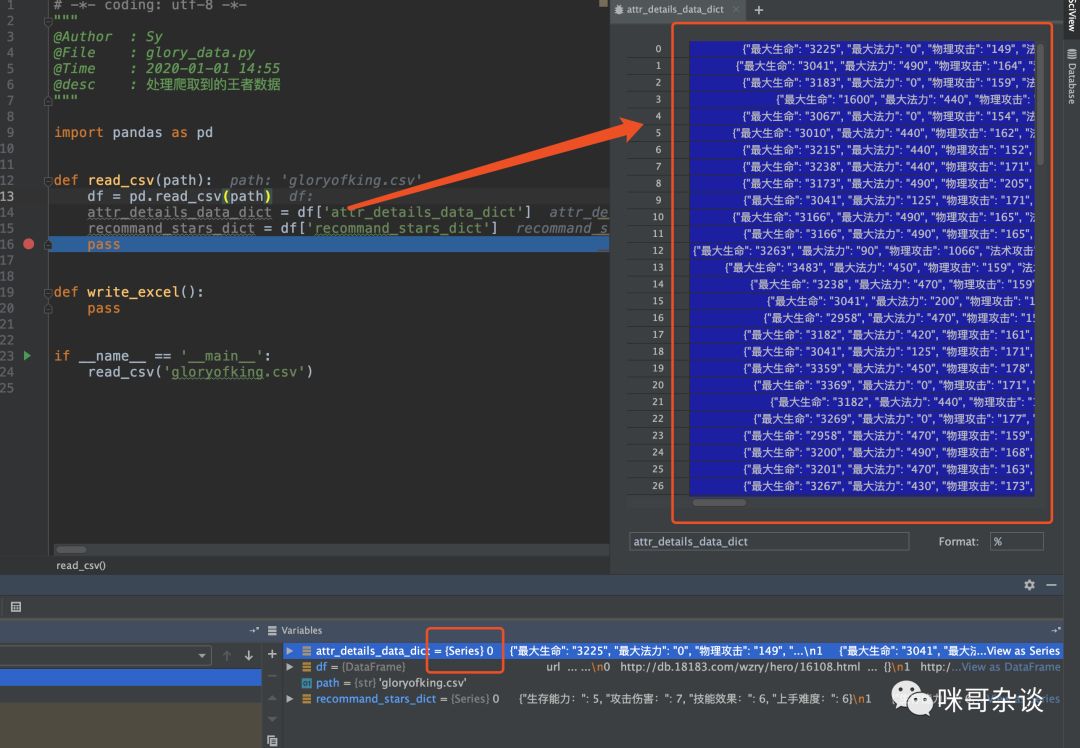
3. pd.DataFrame(dict) 创建新的DataFrame
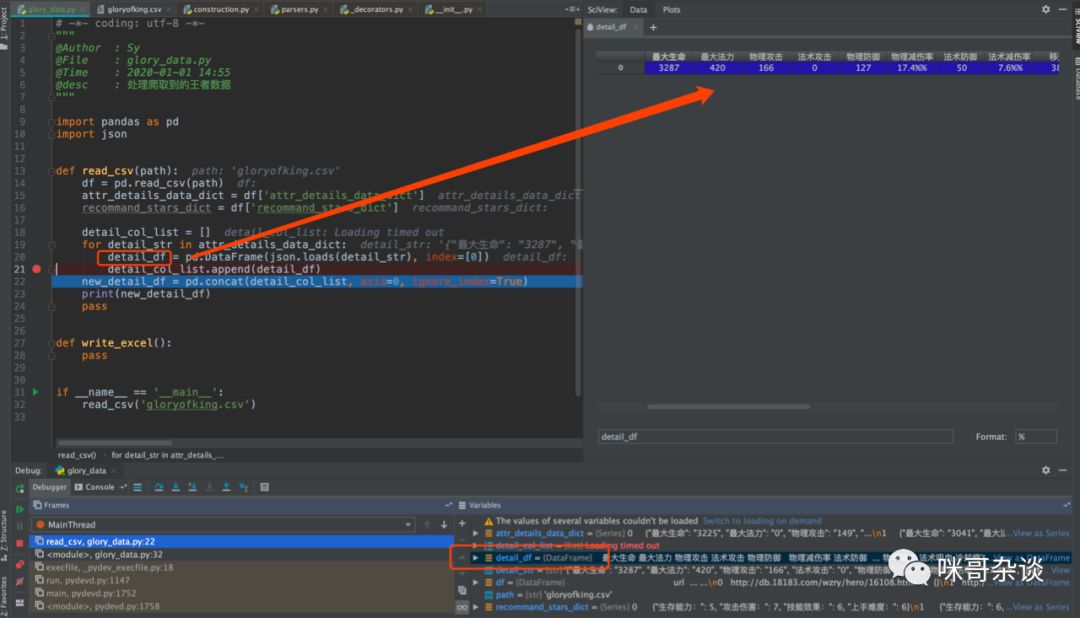
detail_col_list = []for detail_str in attr_details_data_dict:detail_df = pd.DataFrame(json.loads(detail_str), index=[0])detail_col_list.append(detail_df)
不难发现,现在的单列数据中每行看似都是 dict 类型的,但用 for 循环遍历时,取出的数据则是 str 类型,所以要用 json 库转换成 dict。
在用 pd.DataFrame 来构造新的 DataFrame,需要注意,构造时,dict 中的 value 值必须是可迭代的类型,比如 list 等,不然会报错:
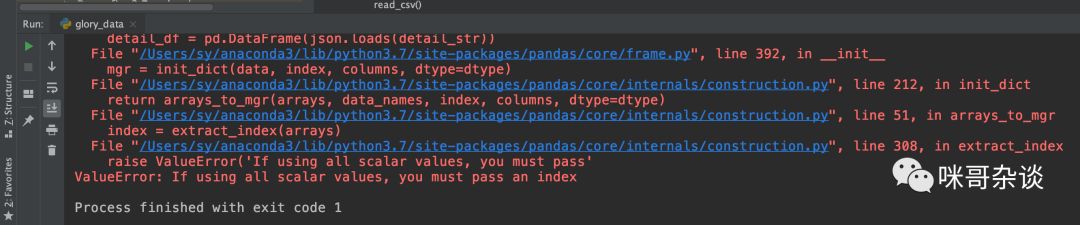
4. pd.concat([df1,df2....]) 合并DataFrame
new_detail_df = pd.concat(detail_col_list, axis=0, ignore_index=True)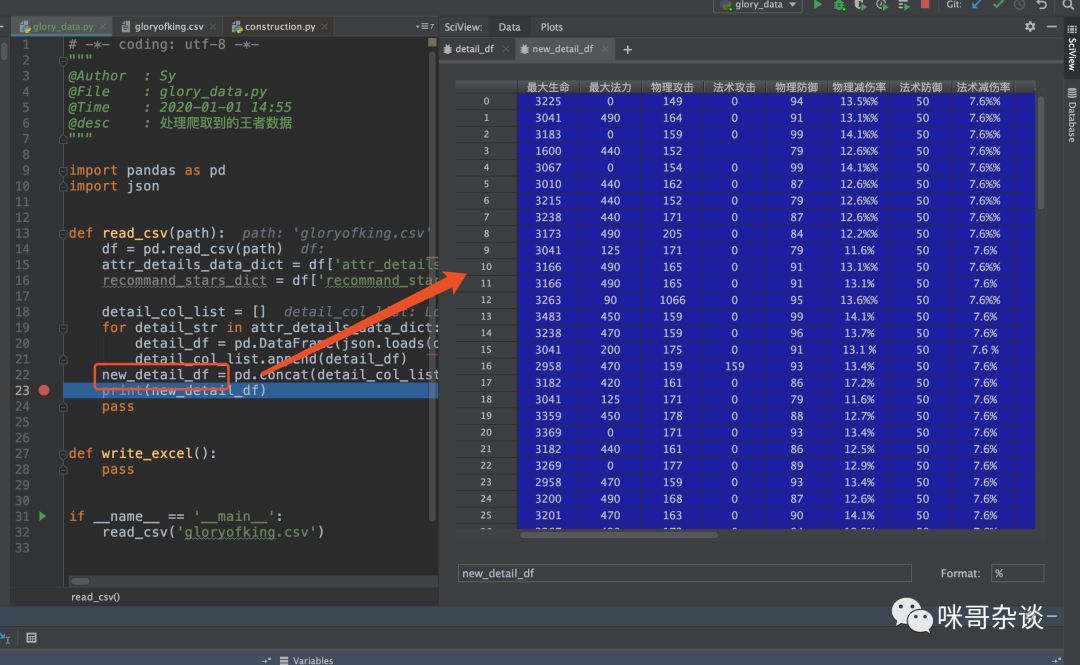
最终,你可以看到由 list 中多个 df 上下合并而成大的 df,和 csv 中的顺序一致,数据一致。
PS : 关于这里的 for 循环,如果你会列表表达式,可以写成一行处理,很简洁:
detail_col_list = [pd.DataFrame(json.loads(detail_str), index=[0]) for detail_str in attr_details_data_dict]
上面四步骤是在处理原来英雄的初始化数值的参数。
原 csv 中还有一列,也是 dict 类型,类似处理即可。
当然如果你对 Excel 处理,以上的后三部也是适用的。
4
pandas写入Excel
写入 Excel 之前,我们有一项工作没有做,就是将我们新增的列合并到原有的 df 上去,把原来 df 中的两个 dict 列去除掉。
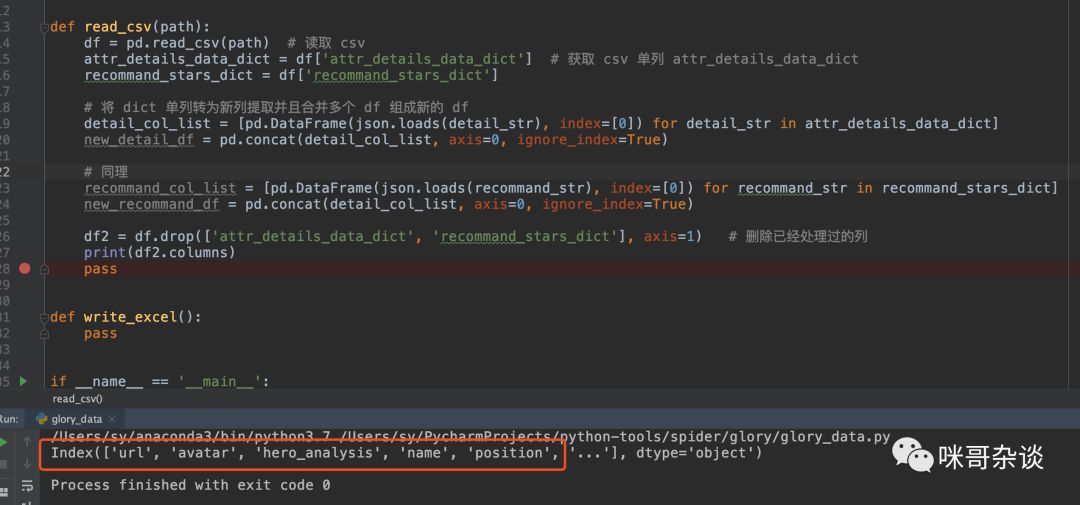
1. 去除 df 中的某列。df.drop(['列名'],axis=1)
df2 = df.drop(['attr_details_data_dict', 'recommand_stars_dict'], axis=1) # 删除已经处理过的列print(df2.columns) # 打印列名
2. 将新增列合并删除后的列上。
依然采用 concat 函数去做合并,这次是左右合并,所以 axis=1 ,列合并(左右), axis=0,行合并(上下)。
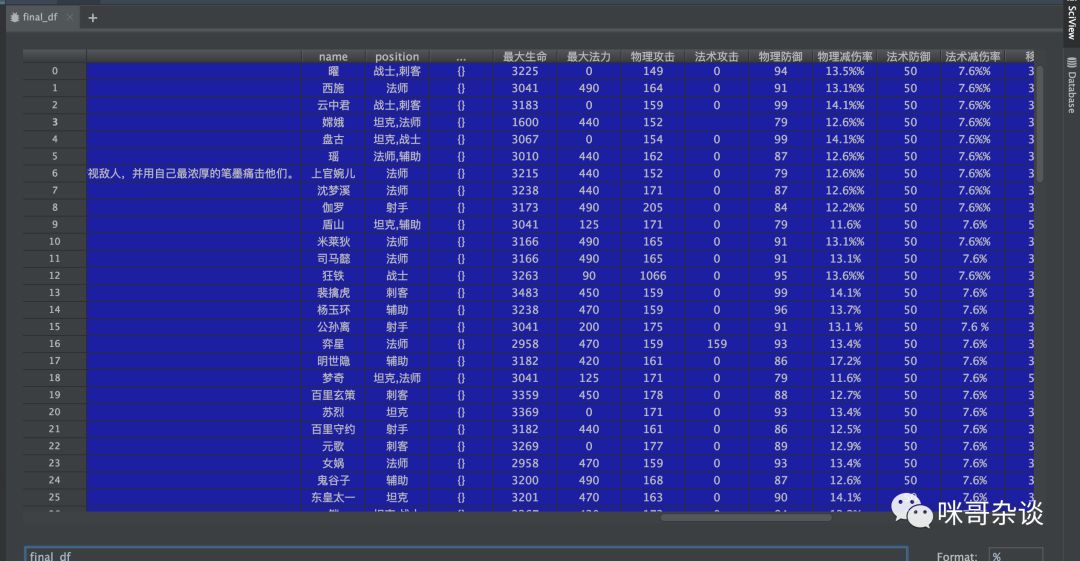
# 合并新旧列final_df = pd.concat([df2, new_detail_df, new_recommend_df], axis=1)
结果:
3. 写入 Excel
写入操作很简单,只需要如下:
final_df.to_excel('xxx.xlsx')5
总结
pandas的操作,已经有了中文的官方文档,非常友好,大家可以对照中文文档去看下。
关于 Excel 中的头像下载,以及 Excel 的数据清理,放在下一篇文章中讲解。本篇内容长度足矣了,不继续写了。
老规矩,本章代码已经上传到 github 上,后台回复 王者数据 ,即可获得源码和excel文件!
pyspider爬取王者荣耀数据(上)
pyspider爬取王者荣耀数据(下)
 你点的每个在看,我都认真当成了喜欢
你点的每个在看,我都认真当成了喜欢