
爬取B站视频排名第一《祖国大好河山》1W+弹幕,得出一份词频词云图
咪哥杂谈

本篇阅读时间约为 7 分钟。
1
前言
在这里,祝我们伟大的祖国 70 周年生日快乐!

翻花长什么样呢?就下面这样。

包括现在街上北京经常看到老大爷老大妈买菜用的小车,应该都是从 60 年国庆那次产出的"历史作物"。
回忆到此结束。
拉回到现在,平时热衷于 B 站的我,扫到了排行榜排名第一的视频,数百位摄影师联合制作,《10分钟带你看绝美祖国大好河山!》
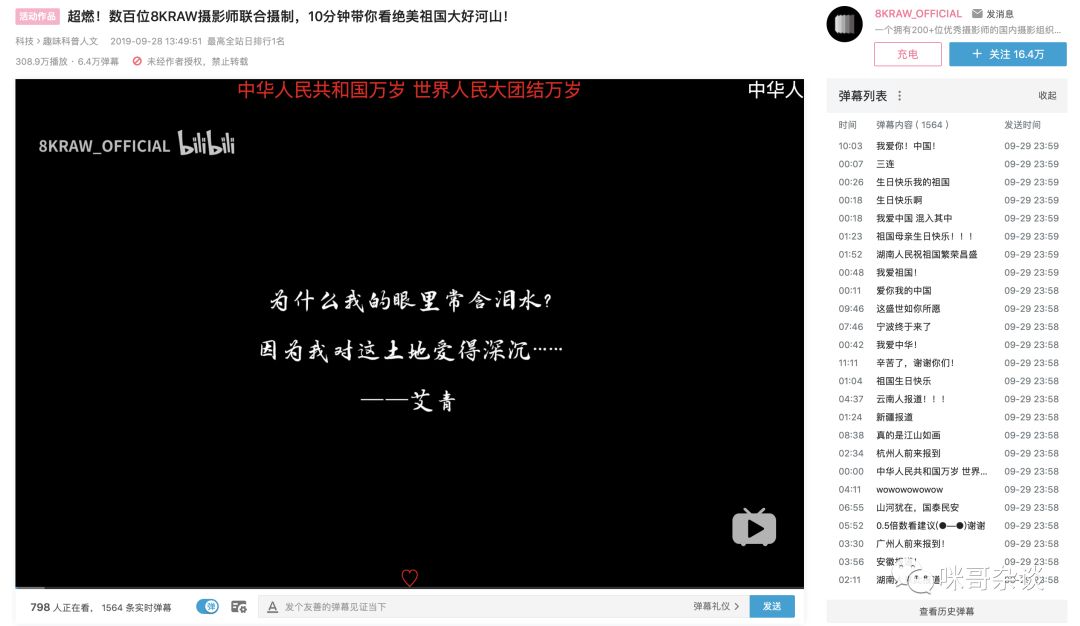
感兴趣的,可以复制下面地址看下:
https://www.bilibili.com/video/av69241910/
B 站
可以看到上图右侧,有数千条弹幕。通过查看历史记录,发现是 9.28 才有的第一条弹幕,目测应该是 9.28 上传的视频。出于感兴趣,于是打算来个词频统计。
文章写到这里,笔者并没有开始代码的编写,也不知道弹幕哪个词出现的频率最高。(平时写文章有个习惯,都是先写前言,搭好文章架子再开始写具体的代码实现。)
在结果出现之前,来个盲猜吧!祖国,快乐。这两个没猜错,应该是最高的频率词!
2
框架性思维
不知道大家还记不记得爬虫的框架步骤。
首先,熟悉网站结构,找出我们想要的数据接口。
其次,分析提取数据。
最后,完成本次的词频统计。
所以,让我们先来找接口吧!B 站的接口很好找哟!
3
B站弹幕接口
打开上述提到的视频链接。
提供一个思路,打开 F12 后,一般默认先去找 XHR 里是否有相似数据。因为 XHR 这栏,是异步请求。意味着,即使不刷新页面,也可以像服务器异步发送请求,不会影响用户操作。
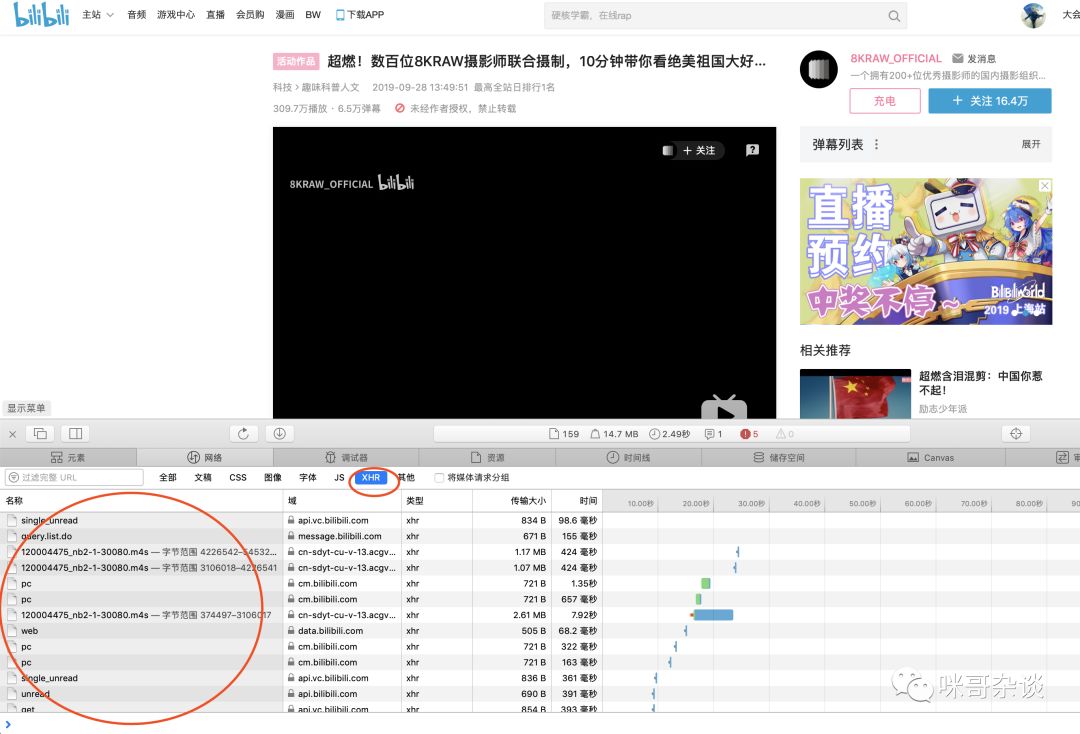
总的来说,下面的异步请求并不多,一个个去看,也能全部浏览完。不过有个小技巧,就是根据名字挑着看,比如那些常见的单词,list。
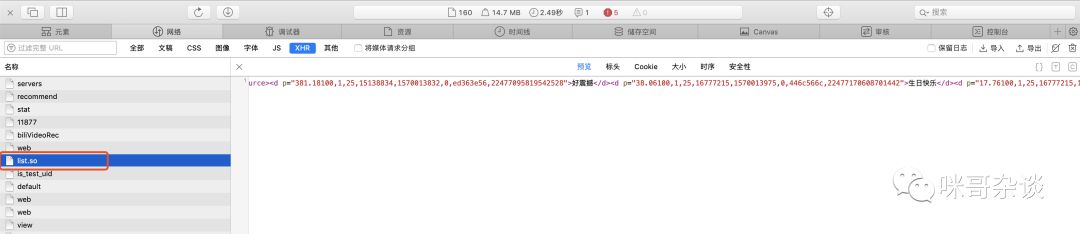
F12看数据,可以看到不是 json 的形式返回的,用浏览器访问下试试。

它是以标签的形式,将数据展示的。而这种形式,恰是之前在小课堂中介绍到的 XML 格式。
其中有个 maxlimit 的标签,数字显示 1500 。猜测应该是此页数据最大 1500 条数据。复制到文本工具里,删除非数据以外的头尾,验证下,一共 1502 行。
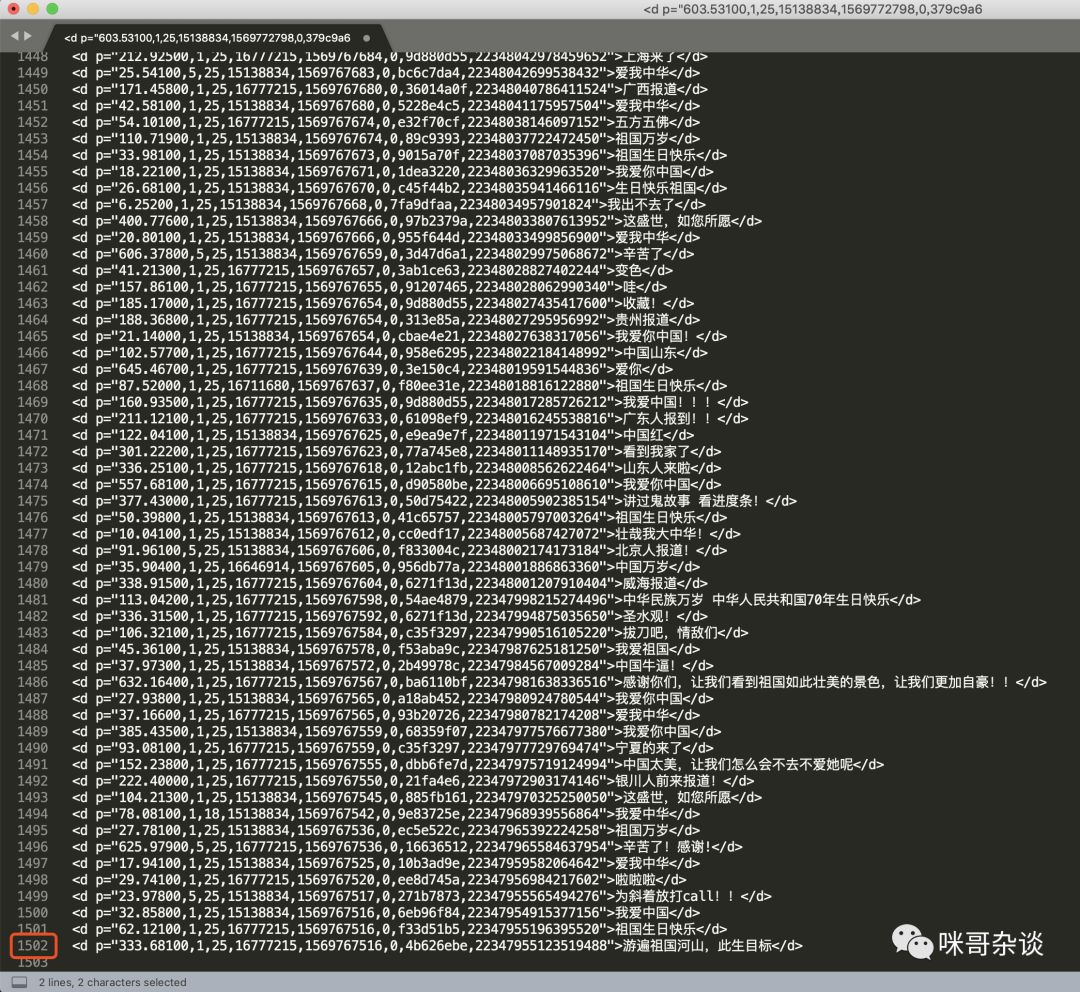
由此得知,这并不是历史数据。继续来挖,点击查看历史,选择9.28日,F12再次看请求。
当然,你可以先清除下之前的F12记录,以免太乱,点击F12的小垃圾桶即可。我这里用的是 Safari 浏览器,谷歌浏览器类似操作。
选择日期:
再次查看:
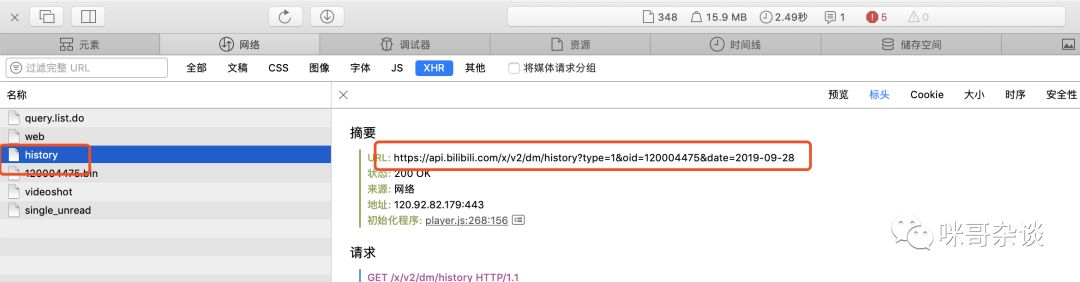
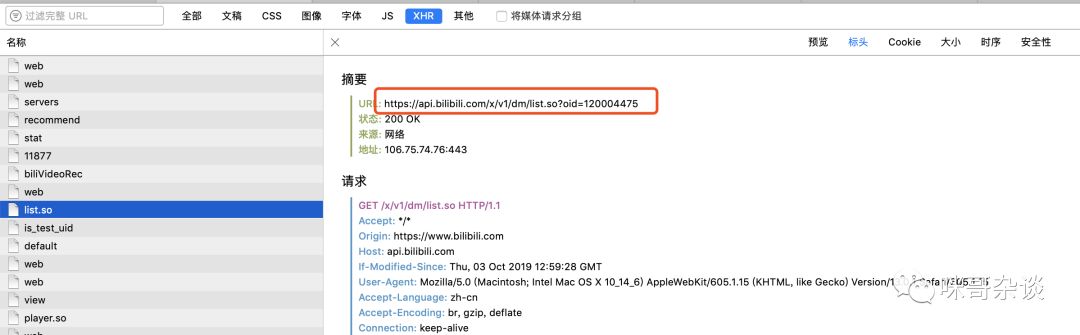
出现了 history 的名字,无疑就是它了!明显,请求地址发生了改变。
https://api.bilibili.com/x/v2/dm/history?type=1&oid=120004475&date=2019-09-28
B站
这样一来,就有了这几天的历史数据。模拟请求,修改下 url 中 date 字段的日期。接下来只需要将返回的 XML 进行数据提取就好啦!
4
代码简说及成果展示
需要的第三方库:
requests
jieba
wordcloud
numpy
PIL
matplotlib
pip install jiebapip install requestpip install wordcloudpip install numpypip install Pillowpip install matplotlib
简单的说下代码思路。
用 requests 库发起模拟请求,请求头需要携带自己的 cookie ,否则会提示请登录的字眼。
爬取弹幕后,存储到一个公有 list 中,通过 jieba 分词的第三方库,对其进行词频统计分析。
其中 jieba 使用的核心代码是这段:
https://github.com/fxsjy/jieba
结巴官网地址

最后,使用 wordcloud 生成词云图核心代码:
def __draw_word(self):""" 词云生成 """d = os.path.dirname(__file__)alice_mask = np.array(Image.open(os.path.join(d, "gq.jpg")))windows_font_path = 'C:/Windows/Fonts/simsun.ttc' # winodws字体mac_font_path = '/System/Library/Fonts/PingFang.ttc' # mac字体wc = WordCloud(font_path=mac_font_path, # 设置字体格式,系统自带的中文字体mask=alice_mask, # 设置背景图background_color='white',max_words=400, # 最多显示词数max_font_size=150 # 字体最大值))wc.generate_from_frequencies(self.word_dict) # 从字典生成词云image_colors = wordcloud.ImageColorGenerator(alice_mask) # 从背景图建立颜色方案wc.recolor(color_func=image_colors) # 将词云颜色设置为背景图方案plt.imshow(wc, interpolation='bilinear') # 显示词云plt.axis('off') # 关闭坐标轴plt.show() # 显示图像
生成词云图时,需要一张原图做"铺垫"。
原图:

渲染:

5
总结
总的来说,盲猜与结果相似度还可以!。。
图片的清晰度有些模糊,可以看到 生日快乐、祖国、我爱你、盛世 字眼相对较大,当然也可以看到中国许多的地名,山东、四川、苏州、山西等等。。。
相信每个看视频的小伙伴,看到自己家乡美景的时候,都会很自豪吧!
本篇文章可以当做一个熟悉词云的练手小项目。从数据角度来看,实用的意义并不是很大!
想看全部源码的同学,后台回复 70 ,即可获得源码地址。
最后的最后,国庆已过一半。假期的你,又有着怎样的合理安排呢?
虽然祝福来的晚了点,依然祝大家国庆快乐!接下来的几天玩的开心~
题图,拍摄于北京坊。
Python玩转高德地图API(二)
Python玩转高德地图API(一)