
硬货来了!轻松掌握 MongDB 流式聚合操作
共 22027字,需浏览 45分钟
· 2019-09-30
“
阅读本文大概需要 15 分钟。
信息科学中的聚合是指对相关数据进行内容筛选、处理和归类并输出结果的过程。MongoDB 中的聚合是指同时对多个文档中的数据进行处理、筛选和归类并输出结果的过程。数据在聚合操作的过程中,就像是水流过一节一节的管道一样,所以 MongoDB 中的聚合又被人称为流式聚合。
MongoDB 提供了几种聚合方式:
•Aggregation Pipeline •Map-Reduce•简单聚合
接下来,我们将全方位地了解 MongoDB 中的聚合。
Aggregation Pipeline
Aggregation Pipeline 又称聚合管道。开发者可以将多个文档传入一个由多个 Stage 组成的 Pipeline,每一个 Stage 处理的结果将会传入下一个 Stage 中,最后一个 Stage 的处理结果就是整个 Pipeline 的输出。
创建聚合管道的语法如下:
db.collection.aggregate([{MongoDB 提供了 23 种 Stage,它们是:
| Stage | 描述 |
$addFields[1] | 向文档添加新字段。 |
$bucket[2] | 根据指定的表达式和存储区边界将传入的文档分组。 |
$bucketAuto[3] | 根据指定的表达式将传入的文档分类为特定数量的组,自动确定存储区边界。 |
$collStats[4] | 返回有关集合或视图的统计信息。 |
$count[5] | 返回聚合管道此阶段的文档数量计数。 |
$facet[6] | 在同一组输入文档的单个阶段内处理多个聚合操作。 |
$geoNear[7] | 基于与地理空间点的接近度返回有序的文档流。 |
$graphLookup[8] | 对集合执行递归搜索。 |
$group[9] | 按指定的标识符表达式对文档进行分组。 |
$indexStats[10] | 返回集合的索引信息。 |
$limit[11] | 将未修改的前 n 个文档传递给管道。 |
$listSessions[12] | 列出system.sessions集合的所有会话。 |
$lookup[13] | 对同一数据库中的另一个集合执行左外连接。 |
$match[14] | 过滤文档,仅允许匹配的文档地传递到下一个管道阶段。 |
$out[15] | 将聚合管道的结果文档写入指定集合,它必须是管道中的最后一个阶段。 |
$project[16] | 为文档添加新字段或删除现有字段。 |
$redact[17] | 可用于实现字段级别的编辑。 |
$replaceRoot[18] | 用指定的嵌入文档替换文档。该操作将替换输入文档中的所有现有字段,包括_id字段。指定嵌入在输入文档中的文档以将嵌入文档提升到顶层。 |
$sample[19] | 从输入中随机选择指定数量的文档。 |
$skip[20] | 跳过前 n 个文档,并将未修改的其余文档传递到下一个阶段。 |
$sort[21] | 按指定的排序键重新排序文档流。只有订单改变; 文件保持不变。对于每个输入文档,输出一个文档。 |
$sortByCount[22] | 对传入文档进行分组,然后计算每个不同组中的文档计数。 |
$unwind[23] | 解构文档中的数组字段。 |
文档、Stage 和 Pipeline 的关系如下图所示:
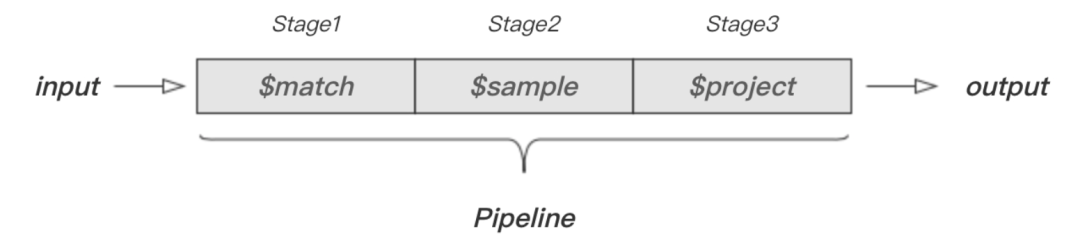 在这里插入图片描述
在这里插入图片描述上图描述了文档经过 $match、$sample 和 $project 等三个 Stage 并输出的过程。SQL 中常见的聚合术语有 WHERE、SUM 和 COUNT 等。下表描述了常见的 SQL 聚合术语、函数和概念以及对应的 MongoDB 操作符或 Stage。
| SQL | MongoDB |
| WHERE | $match[24] |
| GROUP BY | $group[25] |
| HAVING | $match[26] |
| SELECT | $project[27] |
| ORDER BY | $sort[28] |
| LIMIT | $limit[29] |
| SUM() | $sum[30] |
| COUNT() | $sum[31]$sortByCount[32] |
| join | $lookup[33] |
下面,我们将通过示例了解 Aggregate、 Stage 和 Pipeline 之间的关系。
概念浅出
$match 的描述为“过滤文档,仅允许匹配的文档地传递到下一个管道阶段”。其语法格式如下:
{ $match:{在开始学习之前,我们需要准备以下数据:
> db.artic.insertMany([...{"_id":1,"author":"dave","score":80,"views":100},...{"_id":2,"author":"dave","score":85,"views":521},...{"_id":3,"author":"anna","score":60,"views":706},...{"_id":4,"author":"line","score":55,"views":300}...])
然后我们建立只有一个 Stage 的 Pipeline,以实现过滤出 author 为 dave 的文档。对应示例如下:
> db.artic.aggregate([...{$match:{author:"dave"}}...]){"_id":1,"author":"dave","score":80,"views":100}{"_id":2,"author":"dave","score":85,"views":521}
如果要建立有两个 Stage 的 Pipeline,那么就在 aggregate 中添加一个 Stage 即可。现在有这样一个需求:统计集合 artic 中 score 大于 70 且小于 90 的文档数量。这个需求分为两步进行:
•过滤出符合要求的文档•统计文档数量
Aggregation 非常适合这种多步骤的操作。在这个场景中,我们需要用到 $match、$group 这两个 Stage ,然后再与聚合表达式 $sum 相结合,对应示例如下:
> db.artic.aggregate([...{$match:{score:{$gt:70, $lt:90}}},...{$group:{_id:null, number:{$sum:1}}}...]){"_id":null,"number":2}
这个示例的完整过程可以用下图表示:
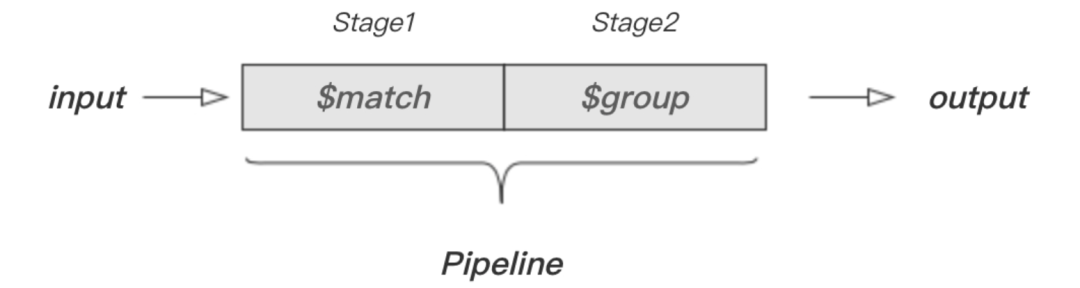 在这里插入图片描述
在这里插入图片描述通过上面的描述和举例,我相信你对 Aggregate、 Stage 和 Pipeline 有了一定的了解。接下来,我们将学习常见的 Stage 的语法和用途。
常见的 Stage
sample
$sample 的作用是从输入中随机选择指定数量的文档,其语法格式如下:
{ $sample:{ size:<positive integer>}}假设要从集合 artic 中随机选择两个文档,对应示例如下:
> db.artic.aggregate([...{$sample:{size:2}}...]){"_id":1,"author":"dave","score":80,"views":100}{"_id":3,"author":"anna","score":60,"views":706}
size 对应的值必须是正整数,如果输入负数会得到错误提示:size argument to $sample must not be negative。要注意的是,当值超过集合中的文档数量时,返回结果是集合中的所有文档,但文档顺序是随机的。
project
$project 的作用是过滤文档中的字段,这与投影操作相似,但处理结果将会传入到下一个阶段 。其语法格式如下:
{ $project:{<specification(s)>}}准备以下数据:
> db.projects.save({_id:1, title:"篮球训练营青春校园活动开始啦", numb:"A829Sck23", author:{last:"quinn", first:"James"}, hot:35})
假设 Pipeline 中的下一个 Stage 只需要文档中的 title 和 author 字段,对应示例如下:
> db.projects.aggregate([{$project:{title:1, author:1}}]){"_id":1,"title":"篮球训练营青春校园活动开始啦","author":{"last":"quinn","first":"James"}}
0 和 1 可以同时存在。对应示例如下:
> db.projects.aggregate([{$project:{title:1, author:1, _id:0}}]){"title":"篮球训练营青春校园活动开始啦","author":{"last":"quinn","first":"James"}}
true 等效于 1,false 等效于 0,也可以混用布尔值和数字,对应示例如下:
> db.projects.aggregate([{$project:{title:1, author:true, _id:false}}]){"title":"篮球训练营青春校园活动开始啦","author":{"last":"quinn","first":"James"}}
如果想要排除指定字段,那么在 $project 中将其设置为 0 或 false 即可,对应示例如下:
> db.projects.aggregate([{$project:{author:false, _id:false}}]){"title":"篮球训练营青春校园活动开始啦","numb":"A829Sck23","hot":35}
$project 也可以作用于嵌入式文档。对于 author 字段,有时候我们只需要 FirstName 或者 Lastname ,对应示例如下:
> db.projects.aggregate([{$project:{author:{"last":false}, _id:false, numb:0}}]){"title":"篮球训练营青春校园活动开始啦","author":{"first":"James"},"hot":35}
这里使用 {author: {"last": false}} 过滤掉 LastName,但保留 first。
以上就是 $project 的基本用法和作用介绍,更多与 $project 相关的知识可查阅官方文档 $project[34]。
lookup
$lookup 的作用是对同一数据库中的集合执行左外连接,其语法格式如下:
{$lookup:{from:<collection to join>,localField:<field from the input documents>,foreignField:<field from the documents of the "from" collection>,as:<output array field>}}
左外连接类似与下面的伪 SQL 语句:
SELECT *,<output array field>FROM collection WHERE <output array field> IN (SELECT * FROM <collection to join> WHERE=<collection.localField>);
lookup 支持的指令及对应描述如下:
| 领域 | 描述 |
from | 指定集合名称。 |
localField | 指定输入 $lookup 中的字段。 |
foreignField | 指定from 给定的集合中的文档字段。 |
as | 指定要添加到输入文档的新数组字段的名称。 新数组字段包含 from集合中的匹配文档。如果输入文档中已存在指定的名称,则会覆盖现有字段 。 |
准备以下数据:
> db.sav.insert([{"_id":1,"item":"almonds","price":12,"quantity":2},{"_id":2,"item":"pecans","price":20,"quantity":1},{"_id":3}])> db.avi.insert([{"_id":1,"sku":"almonds", description:"product 1","instock":120},{"_id":2,"sku":"bread", description:"product 2","instock":80},{"_id":3,"sku":"cashews", description:"product 3","instock":60},{"_id":4,"sku":"pecans", description:"product 4","instock":70},{"_id":5,"sku":null, description:"Incomplete"},{"_id":6}])
假设要连接集合 sav 中的 item 和集合 avi 中的 sku,并将连接结果命名为 savi。对应示例如下:
> db.sav.aggregate([{$lookup:{from:"avi",localField:"item",foreignField:"sku",as:"savi"}}])
命令执行后,输出如下内容:
{"_id":1,"item":"almonds","price":12,"quantity":2,"savi":[{"_id":1,"sku":"almonds","description":"product 1","instock":120}]}{"_id":2,"item":"pecans","price":20,"quantity":1,"savi":[{"_id":4,"sku":"pecans","description":"product 4","instock":70}]}{"_id":3,"savi":[{"_id":5,"sku":null,"description":"Incomplete"},{"_id":6}]}
上面的连接操作等效于下面这样的伪 SQL:
SELECT *, saviFROM savWHERE savi IN (SELECT *FROM aviWHERE sku= sav.item);
以上就是 lookup 的基本用法和作用介绍,更多与 lookup 相关的知识可查阅官方文档 lookup[35]。
unwind
unwind 能将包含数组的文档拆分称多个文档,其语法格式如下:
{$unwind:{path:<field path>,includeArrayIndex:, preserveNullAndEmptyArrays:}}
unwind 支持的指令及对应描述如下:
| 指令 | 类型 | 描述 |
path | string | 指定数组字段的字段路径, 必填。 |
includeArrayIndex | string | 用于保存元素的数组索引的新字段的名称。 |
preserveNullAndEmptyArrays | boolean | 默认情况下,如果path为 null、缺少该字段或空数组, 则不输出文档。反之,将其设为 true 则会输出文档。 |
在开始学习之前,我们需要准备以下数据:
> db.shoes.save({_id:1, brand:"Nick", sizes:[37,38,39]})集合 shoes 中的 sizes 是一个数组,里面有多个尺码数据。假设要将这个文档拆分成 3 个 size 为单个值的文档,对应示例如下:
> db.shoes.aggregate([{$unwind :"$sizes"}]){"_id":1,"brand":"Nick","sizes":37}{"_id":1,"brand":"Nick","sizes":38}{"_id":1,"brand":"Nick","sizes":39}
显然,这样的文档更方便我们做数据处理。preserveNullAndEmptyArrays 指令默认为 false,也就是说文档中指定的 path 为空、null 或缺少该 path 的时候,会忽略掉该文档。假设数据如下:
> db.shoes2.insertMany([{"_id":1,"item":"ABC","sizes":["S","M","L"]},{"_id":2,"item":"EFG","sizes":[]},{"_id":3,"item":"IJK","sizes":"M"},{"_id":4,"item":"LMN"},{"_id":5,"item":"XYZ","sizes":null}])
我们执行以下命令:
> db.shoes2.aggregate([{$unwind:"$sizes"}])就会得到如下输出:
{"_id":1,"item":"ABC","sizes":"S"}{"_id":1,"item":"ABC","sizes":"M"}{"_id":1,"item":"ABC","sizes":"L"}{"_id":3,"item":"IJK","sizes":"M"}
_id 为 2、4 和 5 的文档由于满足 preserveNullAndEmptyArrays 的条件,所以不会被拆分。
以上就是 unwind 的基本用法和作用介绍,更多与 unwind 相关的知识可查阅官方文档 unwind[36]。
out
out 的作用是聚合 Pipeline 返回的结果文档,并将其写入指定的集合。要注意的是,out 操作必须出现在 Pipeline 的最后。out 语法格式如下:
{ $out:"" }准备以下数据:
> db.books.insertMany([{"_id":8751,"title":"The Banquet","author":"Dante","copies":2},{"_id":8752,"title":"Divine Comedy","author":"Dante","copies":1},{"_id":8645,"title":"Eclogues","author":"Dante","copies":2},{"_id":7000,"title":"The Odyssey","author":"Homer","copies":10},{"_id":7020,"title":"Iliad","author":"Homer","copies":10}])
假设要集合 books 的分组结果保存到名为 books_result 的集合中,对应示例如下:
> db.books.aggregate([...{ $group :{_id:"$author", books:{$push:"$title"}}},...{ $out :"books_result"}...])
命令执行后,MongoDB 将会创建 books_result 集合,并将分组结果保存到该集合中。集合 books_result 中的文档如下:
{"_id":"Homer","books":["The Odyssey","Iliad"]}{"_id":"Dante","books":["The Banquet","Divine Comedy","Eclogues"]}
以上就是 out 的基本用法和作用介绍,更多与 out 相关的知识可查阅官方文档 out[37]。
Map-Reduce
Map-reduce 用于将大量数据压缩为有用的聚合结果,其语法格式如下:
db.runCommand({mapReduce:, map:, reduce:, finalize:, out:,query:, sort:, limit:, scope:, jsMode:, verbose:, bypassDocumentValidation:, collation:, writeConcern:})
其中,db.runCommand({mapReduce: 也可以写成 db.collection.mapReduce()。各指令的对应描述如下:
| 指令 | 类型 | 描述 |
mapReduce | collection | 集合名称,必填。 |
map | function | JavaScript 函数,必填。 |
reduce | function | JavaScript 函数,必填。 |
out | string or document | 指定输出结果,必填。 |
query | document | 查询条件语句。 |
sort | document | 对文档进行排序。 |
limit | number | 指定输入到 map 中的最大文档数量。 |
finalize | function | 修改 reduce 的输出。 |
scope | document | 指定全局变量。 |
jsMode | boolean | 是否在执行map和reduce 函数之间将中间数据转换为 BSON 格式,默认 false。 |
verbose | boolean | 结果中是否包含 timing 信息,默认 false。 |
bypassDocumentValidation | boolean | 是否允许 mapReduce[38]在操作期间绕过文档验证,默认 false。 |
collation | document | 指定要用于操作的排序规则[39]。 |
writeConcern | document | 指定写入级别,不填写则使用默认级别。 |
简单的 mapReduce
一个简单的 mapReduce 语法示例如下:
var mapFunction =function(){...};var reduceFunction =function(key, values){...};db.runCommand(...{...... mapReduce:<input-collection>,...... map: mapFunction,...... reduce: reduceFunction,......out:{ merge:<output-collection>},...... query:...})
map 函数负责将每个输入的文档转换为零个或多个文档。map 结构如下:
function(){...emit(key, value);}
emit 函数的作用是分组,它接收两个参数:
•key:指定用于分组的字段。•value:要聚合的字段。
在 map 中可以使用 this 关键字引用当前文档。reduce 结构如下:
function(key, values){...return result;}
reduce 执行具体的数据处理操作,它接收两个参数:
•key:与 map 中的 key 相同,即分组字段。•values:根据分组字段,将相同 key 的值放到同一个数组,values 就是包含这些分类数组的对象。
out 用于指定结果输出,out: 会将结果输出到新的集合,或者使用以下语法将结果输出到已存在的集合中:
out:{: [, db:] [, sharded:] [, nonAtomic:]}
要注意的是,如果 out 指定的 collection 已存在,那么它就会覆盖该集合。在开始学习之前,我们需要准备以下数据:
> db.mprds.insertMany([...{_id:1, numb:3, score:9, team:"B"},...{_id:2, numb:6, score:9, team:"A"},...{_id:3, numb:24, score:9, team:"A"},...{_id:4, numb:6, score:8, team:"A"}...])
接着定义 map 函数、reduce 函数,并将其应用到集合 mrexample 上。然后为输出结果指定存放位置,这里将输出结果存放在名为 mrexample_result 的集合中。
>var func_map =function(){emit(this.numb,this.score);};>var func_reduce =function(key, values){returnArray.sum(values);};> db.mprds.mapReduce(func_map, func_reduce,{query:{team:"A"},out:"mprds_result"})
map 函数指定了结果中包含的两个键,并将 this.class 相同的文档输出到同一个文档中。reduce 则对传入的列表进行求和,求和结果作为结果中的 value 。命令执行完毕后,结果会被存放在集合 mprds_result 中。用以下命令查看结果:
> db.mprds_result.find(){"_id":6,"value":17}{"_id":24,"value":9}
结果文档中的 _id 即 map 中的 this.numb,value 为 reduce 函数的返回值。
下图描述了此次 mapReduce 操作的完整过程:
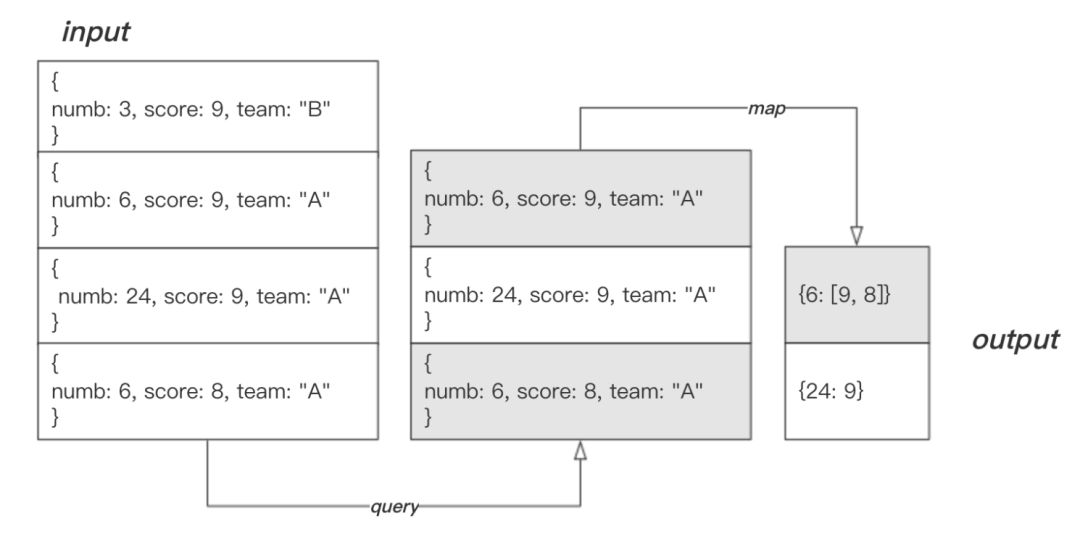 在这里插入图片描述
在这里插入图片描述finallize 剪枝
finallize 用于修改 reduce 的输出结果,其语法格式如下:
function(key, reducedValue){...return modifiedObject;}
它接收两个参数:
key,与 map 中的 key 相同,即分组字段。
reducedValue,一个 Obecjt,是reduce 的输出。
上面我们介绍了 map 和 reduce,并通过一个简单的示例了解 mapReduce 的基本组成和用法。实际上我们还可以编写功能更丰富的 reduce 函数,甚至使用 finallize 修改 reduce 的输出结果。以下 reduce 函数将传入的 values 进行计算和重组,返回一个 reduceVal 对象:
>var func_reduce2 =function(key, values){reduceVal ={team: key, score: values, total:Array.sum(values), count: values.length};return reduceVal;};
reduceVal 对象中包含 team、score、total 和 count 四个属性。但我们还想为其添加 avg 属性,那么可以在 finallize 函数中执行 avg 值的计算和 avg 属性的添加工作:
>var func_finalize =function(key, values){values.avg = values.total / values.count;return values;};
map 保持不变,将这几个函数作用于集合 mprds 上,对应示例如下:
> db.mprds.mapReduce(func_map, func_reduce2,{query:{team:"A"},out:"mprds_result", finalize: func_finalize})命令执行后,结果会存入指定的集合中。此时,集合 mprds_result 内容如下:
{"_id":6,"value":{"team":6,"score":[9,8],"total":17,"count":2,"avg":8.5}}{"_id":24,"value":9}
下图描述了此次 mapReduce 操作的完整过程:
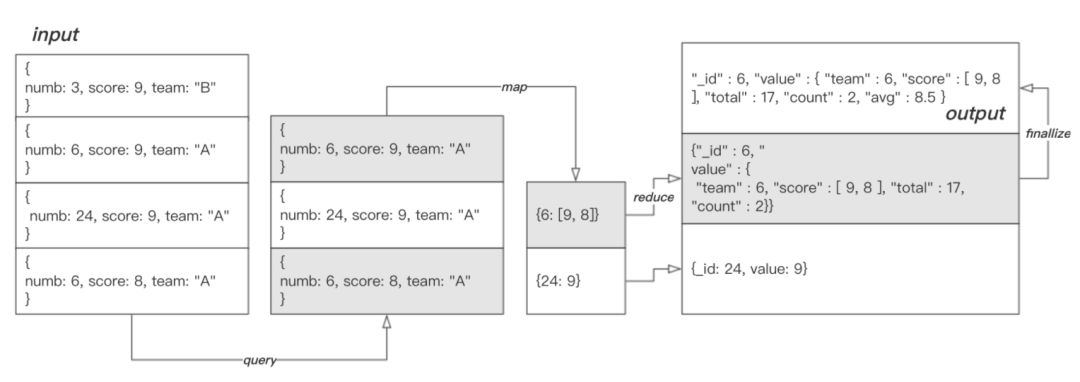 在这里插入图片描述
在这里插入图片描述finallize 在 reduce 后面使用,微调 reduce 的处理结果。这着看起来像是一个园丁在修剪花圃的枝丫,所以人们将 finallize 形象地称为“剪枝”。
要注意的是:map 会将 key 值相同的文档中的 value 归纳到同一个对象中,这个对象会经过 reduce 和 finallize。对于 key 值唯一的那些文档,指定的 key 和 value 会被直接输出。
简单的聚合
除了 Aggregation Pipeline 和 Map-Reduce 这些复杂的聚合操作之外,MongoDB 还支持一些简单的聚合操作,例如 count、group 和 distinct 等。
count
count 用于计算集合或视图中的文档数,返回一个包含计数结果和状态的文档。其语法格式如下:
{count:<collection or view>,query:, limit:, skip:, hint:, readConcern:}
count 支持的指令及对应描述如下:
| 指令 | 类型 | 描述 |
count | string | 要计数的集合或视图的名称,必填。 |
query | document | 查询条件语句。 |
limit | integer | 指定要返回的最大匹配文档数。 |
skip | integer | 指定返回结果之前要跳过的匹配文档数。 |
hint | string or document | 指定要使用的索引,将索引名称指定为字符串或索引规范文档。 |
假设要统计集合 mprds 中的文档数量,对应示例如下:
> db.runCommand({count:'mprds'}){"n":4,"ok":1}
假设要统计集合 mprds 中 numb 为 6 的文档数量,对应示例如下:
> db.runCommand({count:'mprds', query:{numb:{$eq:6}}}){"n":2,"ok":1}
指定返回结果之前跳过 1 个文档,对应示例如下:
> db.runCommand({count:'mprds', query:{numb:{$eq:6}}, skip:1}){"n":1,"ok":1}
更多关于 count 的知识可查阅官方文档 Count[40]。
group
group 的作用是按指定的键对集合中的文档进行分组,并执行简单的聚合函数,它与 SQL 中的 SELECT ... GROUP BY 类似。其语法格式如下:
{group:{ns:, key:, $reduce:<reduce function>,$keyf:<key function>,cond:, finalize:<finalize function>}}
group 支持的指令及对应描述如下:
| 指令 | 类型 | 描述 |
ns | string | 通过操作执行组的集合,必填。 |
key | ducoment | 要分组的字段或字段,必填。 |
$reduce | function | 在分组操作期间对文档进行聚合操作的函数。 该函数有两个参数:当前文档和该组的聚合结果文档。 必填。 |
initial | document | 初始化聚合结果文档, 必填。 |
$keyf | function | 替代 key。指定用于创建“密钥对象”以用作分组密钥的函数。使用 $keyf而不是 key按计算字段而不是现有文档字段进行分组。 |
cond | document | 用于确定要处理的集合中的哪些文档的选择标准。 如果省略, group 会处理集合中的所有文档。 |
finalize | function | 在返回结果之前运行,此函数可以修改结果文档。 |
准备以下数据:
> db.sales.insertMany([{_id:1, orderDate:ISODate("2012-07-01T04:00:00Z"), shipDate:ISODate("2012-07-02T09:00:00Z"), attr:{name:"新款椰子鞋", price:2999, size:42, color:"香槟金"}},{_id:2, orderDate:ISODate("2012-07-03T05:20:00Z"), shipDate:ISODate("2012-07-04T09:00:00Z"), attr:{name:"高邦篮球鞋", price:1999, size:43, color:"狮王棕"}},{_id:3, orderDate:ISODate("2012-07-03T05:20:10Z"), shipDate:ISODate("2012-07-04T09:00:00Z"), attr:{name:"新款椰子鞋", price:2999, size:42, color:"香槟金"}},{_id:4, orderDate:ISODate("2012-07-05T15:11:33Z"), shipDate:ISODate("2012-07-06T09:00:00Z"), attr:{name:"极速跑鞋", price:500, size:43, color:"西湖蓝"}},{_id:5, orderDate:ISODate("2012-07-05T20:22:09Z"), shipDate:ISODate("2012-07-06T09:00:00Z"), attr:{name:"新款椰子鞋", price:2999, size:42, color:"香槟金"}},{_id:6, orderDate:ISODate("2012-07-05T22:35:20Z"), shipDate:ISODate("2012-07-06T09:00:00Z"), attr:{name:"透气网跑", price:399, size:38, color:"玫瑰红"}}])
假设要将集合 sales 中的文档按照 attr.name 进行分组,并限定参与分组的文档的 shipDate 大于指定时间。对应示例如下:
> db.runCommand({group:{ns:'sales',key:{"attr.name":1},cond:{shipDate:{$gt:ISODate('2012-07-04T00:00:00Z')}},$reduce:function(curr, result){},initial:{}}})
命令执行后,会返回一个结果档。其中, retval 包含指定字段 attr.name 的数据,count 为参与分组的文档数量,keys 代表组的数量,ok 代表文档状态。结果文档如下:
{"retval":[{"attr.name":"高邦篮球鞋"},{"attr.name":"新款椰子鞋"},{"attr.name":"极速跑鞋"},{"attr.name":"透气网跑"}],"count":NumberLong(5),"keys":NumberLong(4),"ok":1}
上方示例指定的 key 是 attr.name。由于参与分组的 5 个文档中只有 2 个文档的 attr.name 是相同的,所以分组结果中的 keys 为 4,这代表集合 sales 中的文档被分成了 4 组。
将 attr.name换成 shipDate,看看结果会是什么。对应示例如下:
> db.runCommand({group:{ns:'sales',key:{shipDate:1},cond:{shipDate:{$gt:ISODate('2012-07-04T00:00:00Z')}},$reduce:function(curr, result){},initial:{}}})
命令执行后,返回如下结果:
{"retval":[{"shipDate":ISODate("2012-07-04T09:00:00Z")},{"shipDate":ISODate("2012-07-06T09:00:00Z")}],"count":NumberLong(5),"keys":NumberLong(2),"ok":1}
由于参与分组的 5 个文档中有几个文档的 shipDate 是重复的,所以分组结果中的 keys 为 2,这代表集合 sales 中的文档被分成了 2 组。
上面的示例并没有用到 reduce、 initial 和 finallize ,接下来我们将演示它们的用法和作用。假设要统计同组的销售总额,那么可以在 reduce 中执行具体的计算逻辑。对应示例如下:
> db.runCommand({group:{ns:'sales',key:{shipDate:1},cond:{shipDate:{$gt:ISODate('2012-07-04T00:00:00Z')}},$reduce:function(curr, result){result.total += curr.attr.price;},initial:{total:0}}})
命令执行后,返回结果如下:
{"retval":[{"shipDate":ISODate("2012-07-04T09:00:00Z"),"total":4998},{"shipDate":ISODate("2012-07-06T09:00:00Z"),"total":3898}],"count":NumberLong(5),"keys":NumberLong(2),"ok":1}
人工验证一下,发货日期 shipDate 大于 2012-07-04T09:00:00Z 的文档为:
{"_id":2,"orderDate":ISODate("2012-07-03T05:20:00Z"),"shipDate":ISODate("2012-07-04T09:00:00Z"),"attr":{"name":"高邦篮球鞋","price":1999,"size":43,"color":"狮王棕"}}{"_id":3,"orderDate":ISODate("2012-07-03T05:20:10Z"),"shipDate":ISODate("2012-07-04T09:00:00Z"),"attr":{"name":"新款椰子鞋","price":2999,"size":42,"color":"香槟金"}}
销售总额为 1999 + 2999 = 4998,与返回结果相同。发货日期 shipDate 大于 2012-07-06T09:00:00Z 的文档为:
{"_id":4,"orderDate":ISODate("2012-07-05T15:11:33Z"),"shipDate":ISODate("2012-07-06T09:00:00Z"),"attr":{"name":"极速跑鞋","price":500,"size":43,"color":"西湖蓝"}}{"_id":5,"orderDate":ISODate("2012-07-05T20:22:09Z"),"shipDate":ISODate("2012-07-06T09:00:00Z"),"attr":{"name":"新款椰子鞋","price":2999,"size":42,"color":"香槟金"}}{"_id":6,"orderDate":ISODate("2012-07-05T22:35:20Z"),"shipDate":ISODate("2012-07-06T09:00:00Z"),"attr":{"name":"透气网跑","price":399,"size":38,"color":"玫瑰红"}}
销售总额为 500 + 2999 + 399 = 3898,与返回结果相同。
有时候可能需要统计每个组的文档数量以及计算平均销售额,对应示例如下:
> db.runCommand({group:{ns:'sales',key:{shipDate:1},cond:{shipDate:{$gt:ISODate('2012-07-04T00:00:00Z')}},$reduce:function(curr, result){result.total += curr.attr.price;result.count ++;},initial:{total:0, count:0},finalize:function(result){result.avg =Math.round(result.total / result.count);}}})
上面的示例中改动了 $reduce 函数,目的是为了统计 count。然后新增了 finalize,目的是计算分组中的平均销售额。命令执行后,返回以下文档:
{"retval":[{"shipDate":ISODate("2012-07-04T09:00:00Z"),"total":4998,"count":2,"avg":2499},{"shipDate":ISODate("2012-07-06T09:00:00Z"),"total":3898,"count":3,"avg":1299}],"count":NumberLong(5),"keys":NumberLong(2),"ok":1}
以上就是 group 的基本用法和作用介绍,更多与 group 相关的知识可查阅官方文档 group[41]。
distinct
distinct 的作用是查找单个集合中指定字段的不同值,其语法格式如下:
{distinct:"" ,key:"" ,query:, readConcern:<read concern document>,collation:<collation document>}
distinct 支持的指令及对应描述如下:
| 指令 | 类型 | 描述 |
distinct | string | 集合名称, 必填。 |
key | string | 指定的字段, 必填。 |
query | document | 查询条件语句。 |
readConcern | document | |
collation | document |
准备以下数据:
> db.dress.insertMany([...{_id:1,"dept":"A", attr:{"款式":"立领", color:"red"}, sizes:["S","M"]},...{_id:2,"dept":"A", attr:{"款式":"圆领", color:"blue"}, sizes:["M","L"]},...{_id:3,"dept":"B", attr:{"款式":"圆领", color:"blue"}, sizes:"S"},...{_id:4,"dept":"A", attr:{"款式":"V领", color:"black"}, sizes:["S"]}])
假设要统计集合 dress 中所有文档的 dept 字段的不同值,对应示例如下:
> db.runCommand ({ distinct:"dress", key:"dept"}){"values":["A","B"],"ok":1}
或者看看有那些款式,对应示例如下
> db.runCommand ({ distinct:"dress", key:"attr.款式"}){"values":["立领","圆领","V领"],"ok":1}
就算值是数组, distinct 也能作出正确处理,对应示例如下:
> db.runCommand ({ distinct:"dress", key:"sizes"}){"values":["M","S","L"],"ok":1}
流式聚合操作小结
以上就是本篇对 MongoDB 中流式聚合操作的介绍。聚合与管道的概念并不常见,但是理解起来也不难。只要跟着示例思考,并动手实践,相信你很快就能够熟练掌握聚合操作。
推荐阅读
1
2
跟繁琐的模型说拜拜!深度学习脚手架 ModelZoo 来袭!
3
4
妈妈再也不用担心爬虫被封号了!手把手教你搭建Cookies池
崔庆才
静觅博客博主,《Python3网络爬虫开发实战》作者
隐形字
个人公众号:进击的Coder


长按识别二维码关注
References
[1] $addFields: https://docs.mongodb.com/manual/reference/operator/aggregation/addFields/#pipe._S_addFields[2] $bucket: https://docs.mongodb.com/manual/reference/operator/aggregation/bucket/#pipe._S_bucket[3] $bucketAuto: https://docs.mongodb.com/manual/reference/operator/aggregation/bucketAuto/#pipe._S_bucketAuto[4] $collStats: https://docs.mongodb.com/manual/reference/operator/aggregation/collStats/#pipe._S_collStats[5] $count: https://docs.mongodb.com/manual/reference/operator/aggregation/count/#pipe._S_count[6] $facet: https://docs.mongodb.com/manual/reference/operator/aggregation/facet/#pipe._S_facet[7] $geoNear: https://docs.mongodb.com/manual/reference/operator/aggregation/geoNear/#pipe._S_geoNear[8] $graphLookup: https://docs.mongodb.com/manual/reference/operator/aggregation/graphLookup/#pipe._S_graphLookup[9] $group: https://docs.mongodb.com/manual/reference/operator/aggregation/group/#pipe._S_group[10] $indexStats: https://docs.mongodb.com/manual/reference/operator/aggregation/indexStats/#pipe._S_indexStats[11] $limit: https://docs.mongodb.com/manual/reference/operator/aggregation/limit/#pipe._S_limit[12] $listSessions: https://docs.mongodb.com/manual/reference/operator/aggregation/listSessions/#pipe._S_listSessions[13] $lookup: https://docs.mongodb.com/manual/reference/operator/aggregation/lookup/#pipe._S_lookup[14] $match: https://docs.mongodb.com/manual/reference/operator/aggregation/match/#pipe._S_match[15] $out: https://docs.mongodb.com/manual/reference/operator/aggregation/out/#pipe._S_out[16] $project: https://docs.mongodb.com/manual/reference/operator/aggregation/project/#pipe._S_project[17] $redact: https://docs.mongodb.com/manual/reference/operator/aggregation/redact/#pipe._S_redact[18] $replaceRoot: https://docs.mongodb.com/manual/reference/operator/aggregation/replaceRoot/#pipe._S_replaceRoot[19] $sample: https://docs.mongodb.com/manual/reference/operator/aggregation/sample/#pipe._S_sample[20] $skip: https://docs.mongodb.com/manual/reference/operator/aggregation/skip/#pipe._S_skip[21] $sort: https://docs.mongodb.com/manual/reference/operator/aggregation/sort/#pipe._S_sort[22] $sortByCount: https://docs.mongodb.com/manual/reference/operator/aggregation/sortByCount/#pipe._S_sortByCount[23] $unwind: https://docs.mongodb.com/manual/reference/operator/aggregation/unwind/#pipe._S_unwind[24] $match: https://docs.mongodb.com/manual/reference/operator/aggregation/match/#pipe._S_match[25] $group: https://docs.mongodb.com/manual/reference/operator/aggregation/group/#pipe._S_group[26] $match: https://docs.mongodb.com/manual/reference/operator/aggregation/match/#pipe._S_match[27] $project: https://docs.mongodb.com/manual/reference/operator/aggregation/project/#pipe._S_project[28] $sort: https://docs.mongodb.com/manual/reference/operator/aggregation/sort/#pipe._S_sort[29] $limit: https://docs.mongodb.com/manual/reference/operator/aggregation/limit/#pipe._S_limit[30] $sum: https://docs.mongodb.com/manual/reference/operator/aggregation/sum/#grp._S_sum[31] $sum: https://docs.mongodb.com/manual/reference/operator/aggregation/sum/#grp._S_sum[32] $sortByCount: https://docs.mongodb.com/manual/reference/operator/aggregation/sortByCount/#pipe._S_sortByCount[33] $lookup: https://docs.mongodb.com/manual/reference/operator/aggregation/lookup/#pipe._S_lookup[34] $project: https://docs.mongodb.com/manual/reference/operator/aggregation/project/#project-aggregation[35] lookup: https://docs.mongodb.com/manual/reference/operator/aggregation/lookup/#lookup-aggregation[36] unwind: https://docs.mongodb.com/manual/reference/operator/aggregation/unwind/#unwind-aggregation[37] out: https://docs.mongodb.com/manual/reference/operator/aggregation/out/#out-aggregation[38] mapReduce: https://docs.mongodb.com/manual/reference/command/mapReduce/#dbcmd.mapReduce[39] 排序规则: https://docs.mongodb.com/manual/reference/bson-type-comparison-order/#collation[40] Count: https://docs.mongodb.com/manual/reference/command/count/#count[41] group: https://docs.mongodb.com/manual/reference/command/group/#group