
太强了!鹅厂程序员“自研”脚本语言 eben
共 65321字,需浏览 131分钟
· 2023-10-13
 # 关注并星标腾讯云开发者
# 关注并星标腾讯云开发者
# 每周4 | 鹅厂一线程序员,为你“试毒”新技术
# 第5期 | 腾讯donghui:从0到1:如何设计实现一门自己的脚本语言?


|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|

a := (base + 10.2) / 2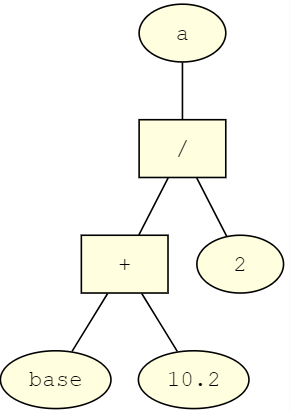
var a = (base + 10.2) / 2;
a := (base + 10.2) / 20000 1 OP_GET_GLOBAL 1 'base'0002 | OP_CONSTANT 2 '10.2'0004 | OP_ADD0005 | OP_CONSTANT 3 '2'0007 | OP_DIVIDE0008 | OP_DEFINE_GLOBAL 0 'a'0010 2 OP_NIL0011 | OP_RETURN
文中主要知识来自于 Robert Nystrom 的 "Crafting Interpreters" 和 Roberto Ierusalimschy 的 "The Implementation of Lua 5.0" 以及 "The Design of Lua"。

3.1 基础概念
3.1.1 BNF 范式
print "hello" + " world";print 5 > 9;print 4 * 9 + -8 / 2;printStmt -> "print" expression ";" ;expression -> ...| comparison | ... ;comparison -> term (">" | ">=" | "<" | "<=") term ;
term -> factor ( ( "-" | "+") factor )* ;factor -> unary ( ( "/" | "*" ) unary )* ;
class Bird {fly() { print "Hi, sky!"; }}class Canary : Bird {eat() {}}
classDecl -> "class" IDENTIFIER ( ":" IDENTIFIER)? "{" function* "}" ;function -> IDENTIFIER "(" parameters? ")" block ;parameters -> IDENTIFIER ( "," IDENTIFIER )* ;IDENTIFIER -> ALPHA ( ALPHA | DIGIT )* ;
3.1.2 字节码
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0000 1 OP_CONSTANT 1 'hello' // 创建字面常量 "hello"0002 | OP_CONSTANT 2 'world' // 创建字面常量 "world"0004 | OP_ADD // 字符串拼接0005 | OP_DEFINE_GLOBAL 0 'b' // 定义全局变量 b0007 2 OP_GET_GLOBAL 3 'b' // 获取全局变量 b0009 | OP_PRINT // 打印
3.1.3 虚拟机
typedef struct { CallFrame frames[FRAMES_MAX]; // 函数调用栈Value stack[STACK_MAX]; // 值栈Value *stackPop; // 栈顶指针Table globals; // 全局表,存放变量、函数ObjUpvalue *openUpvalues; // 闭包值链表,用于存放函数闭包所需的参数Obj *objects; // 对象链表,用于垃圾回收等 ...} VM;
Result run() {for(;;) {switch(instruction = READ_BYTE()) { // 获取下一条字节码case OP_CONSTANT: ...;break;case OP_POP: pop();break;case OP_GET_GLOBAL: ...;break;case OP_ADD: ...;break;case OP_CLOSURE: ...;break;case OP_CLASS: push(OBJ_VAL(newClass(READ_STRING())));break; // 创建类对象...}}}
3.2 词法扫描
NUMBER -> DIGIT+ ( "." DIGIT+ )? ; // 数值IDENTIFIER -> ALPHA ( ALPHA | DIGIT )* ; // 标识符ALPHA -> "a" ... "z" | "A" .. "Z" | "_" ; // 字母(包含下划线)DIGIT -> "0" ... "9" ; // 数字STRING -> '"' (^")* '"' ; // 字符串(^" 表示非引号)
// 是否是字母或下划线bool isAlpha(char c) {return (c >= 'a' && c <= 'z') || (c >= 'A' && c <= 'Z') || c == '_';}// 是否是数字bool isDigit(char c) { return c >= '0' && c <= '9'; }// 扫描数字Token number() {while(isDigit(peek(0))advance(); // 游标前进// 小数部分if(peek(0) == '.' && isDigit(peek(1))) {advance();while(isDigit(peek(0)))advance();}return makeToken(TOKEN_NUMBER);}// 扫描字符串Token string() {while(peek(0) != '"' && !isAtEnd()) {advance();}if(isAtEnd())return error("未收尾的字符串");advance();return makeToken(TOKEN_STRING);}
Token scan() {char c = advance();if(isAlpha(c)) // 检测到字母或下划线return identifer(); // 扫描标识符if(isDigit(c)) // 检测到数字return number(); // 扫描数值switch(c) {case '+': return makeToken(TOKEN_PLUS); // 扫描加法符号// 依据下个字符的情况,扫描小于等于号,或者小于号case '<': return makeToken(match('=') ? TOKEN_LESS_EQUAL : TOKEN_LESS);...case '"': return string(); // 扫描字符串,直到遇到收尾双引号}// 遇到无法匹配的字符,报错return error("未识别字符");}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
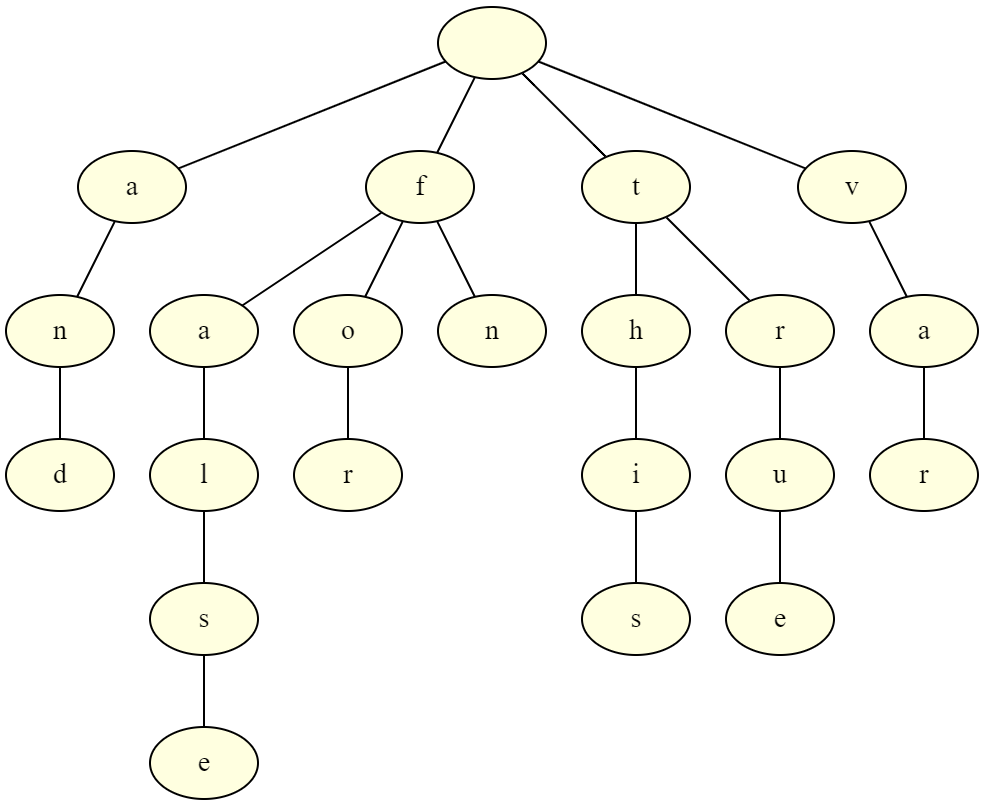
swtich(c1) {case 'a': return checkReserved("nd", TOKEN_AND); // checkReserved 判断剩下的字符串是否相同,同则返回 TOKEN_ANDcase 'f': {...switch(c2) {case 'a': return checkReserved("lse", TOKEN_FALSE); // f + a + lse 三部分都匹配的话,返回 TOKEN_FALSEcase 'o': return checkReserved("r", TOKEN_FOR);case 'n': return checkReserved("", TOKEN_FUNC);}}case 'v': return checkReserved("ar", TOKEN_VAR);...}return TOKEN_IDENTIFIER; // 没有匹配,说明不是保留关键字
3.3 语法解析
// 程序代码由任意条声明加上文件结束符组成program -> decl* EOF ;// 声明可以是类声明、函数声明、变量声明等,还可以是语句decl -> classDecl | funcDecl | varDecl | stmt ;// 语句可以是表达式语句,for循环,if条件,打印,返回,while循环,区块等stmt -> exprStmt | forStmt | ifStmt | printStmt | returnStmt | whileStmt | block ;
void compile(const char *source) {...scan(); // 完成词法扫描while(!match(TOKEN_EOF)) {declaration(); // 循环解析声明语句,直到文件结束}...}static void declaration() {if(match(TOKEN_CLASS)) {classDeclaration(); // 解析类声明} else if(match(TOKEN_FUNC)) {funcDeclaration(); // 解析函数声明} else if(match(TOKEN_VAR)) {varDeclaration(); // 解析变量声明} else {statement(); // 解析其他语句}}static void statement() {if(match(TOKEN_PRINT)) {printStatement(); // 解析打印语句} else if(match(TOKEN_FOR)) {forStatement(); // 解析 for 循环语句}... // 解析其他语句else {expressionStatement(); // 解析表达式语句}}...
static void funcDeclaration() {uint8_t funcNameIndex = parseVariable("此处需要函数名"); // 解析函数名标识符,失败则报错consumeToken(TOKEN_LEFT_PAREN, "需要左括号"); // 完成左括号解析,不存在则报错if(!check(TOKEN_RIGHT_PAREN)) { // 如果下一个token不是右括号,代表有函数形参列表do {uint8_t paramNameIndex = parseVariable("需要形式参数名称");defineVariable(paramNameIndex);} while(match(TOKEN_COMMA)); // 遇到逗号代表还有参数,循环解析下去}consumeToken(TOKEN_RIGHT_PAREN, "需要右括号"); // 完成右括号解析,不存在则报错consumeToken(TOKEN_LEFT_BRACE, "需要左花括号"); // 完成左花括号解析,不存在则报错block(); // 解析函数体,函数体是一个区块 block...defineVariable(funcNameIndex); // 将函数名放入全局表中}
3.4 底层数据结构
typedef enum {VAL_BOOL, // 布尔类型VAL_NIL, // 空类型VAL_NUMBER, // 数值类型VAL_OBJ // 对象类型} ValueType;
typedef struct {ValueType type; // 数据类型// 使用联合实现空间复用,节约内存union {bool boolean; // C 中 bool 类型来表示 eben 布尔类型double number; // C 中 double 类型来表示 eben 数值类型Obj *obj; // C 中 Obj* 指针来指向动态分配的复杂结构} as;} Value;
typedef enum {OBJ_CLASS, // 类OBJ_CLOSURE, // 闭包OBJ_FUNCTION, // 函数OBJ_INSTANCE, // 实例OBJ_NATIVE, // 本地函数OBJ_STRING, // 字符串OBJ_UPVALUE, // 闭包参数} ObjType;struct Obj {ObjType type; // Object 类型bool isMarked; // 用于 GC 标记,下文将介绍struct Obj *next; // 链表指针}
typedef struct {Obj obj; // 元信息int length;char *chars;} ObjString;typedef struct {Obj obj; // 元信息ObjString *name;Table methods;} ObjClass;
void freeObject(Obj *object) {switch(object->type) {case OBJ_CLASS: {ObjClass *klass = (ObjClass *)object;freeTable(&klass->methods);FREE(ObjClass, object);break;}case OBJ_STRING: {ObjString *string = (ObjString *)object;FREE_ARRAY(char, string->chars, string->length+1);FREE(ObjString, object);break;}... // 其他类型对象的释放}}
3.5 变量
3.5.1 全局变量
varDecl -> "var" IDENTIFIER ( "=" expression )? ";" ;var abc = "hello"; // 赋值 "hello"var bcd; // 没有赋初始值,默认为 nil
static void varDeclaration() {uint8_t global = parseVariable("需要变量名"); // 解析变量名,获取序号if(match(TOKEN_EQUAL)) {expression(); // 继续解析等于号右侧的表达式,此处就是 "hello" 字符串} else {emitByte(OP_NIL); // 直接生成压入空值字节码}consumeToken(TOKEN_SEMICOLON, "声明结尾需要分号");emitBytes(OP_DEFINE_GLOBAL, global); // 带入序号,生成定义变量字节码}
case OP_DEFINE_GLOBAL: {ObjString *name = READ_STRING_FROM_CONSTANTS(); // 从常量列表中取出之前暂存的变量名tableSet(&vm.globals, name, peek(0)); // peek(0) 取出值栈的栈顶元素pop(); // 使用完成,弹出栈顶元素break;}
case OP_GET_GLOBAL: {ObjString *name = READ_STRING_FROM_CONSTANTS(); // 获得变量名 "abc"Value value;if(!tableGet(&vm.globals, name, &value)) { // 用 "abc" 去全局表中查找,找到则将值回填到 value 中runtimeError("未定义变量 %s", name->chars); // 如果没找到,报“未定义的变量”错误return RUNTIME_ERROR;}push(value); // 如果存在,压入值栈待后续使用break;}
case OP_PRINT:printValue(pop());break;
3.5.2 局部变量
int arg = resolveLocal(current, &name); // 尝试查找局部变量,递归向外执行if(arg != -1) {op = OP_GET_LOCAL;} else {op = OP_GET_GLOBAL;}emitBytes(op, arg); // 传入变量序号,生成获取变量字节码
case OP_GET_LOCAL: {uint8_t index = READ_BYTE(); // 在字节码数据中读出上文代码中传入的 arg,即变量序号push(vm.stack[index]); // 将序号对应的值压入栈顶,以备后续使用break;}
3.6 条件控制
3.6.1 if 语句
if(true) {print "hi";}print "hello";
0000 1 OP_TRUE // 将布尔值 true 压入值栈0001 | OP_JUMP_IF_FALSE 1 -> 11 // 如果为假,跳到 0011 处0004 | OP_POP // 弹出栈顶值0005 2 OP_CONSTANT 0 'hi'0007 | OP_PRINT0008 3 OP_JUMP 8 -> 12 // 无条件跳到 0012 处0011 | OP_POP // 弹出栈顶值0012 4 OP_CONSTANT 1 'hello'0014 | OP_PRINT
static void ifStatement() {consumeToken(TOKEN_LEFT_PAREN, "需要左括号"); // 完成左括号解析,不存在则报错expression(); // 解析括号中的条件表达式consumeToken(TOKEN_RIGHT_PAREN, "需要右括号");int thenJump = emitJump(OP_JUMP_IF_FALSE); // 生成条件跳跃字节码emitByte(OP_POP); // 弹出条件表达式的值,用完即丢statement(); // 解析 if 分支中语句int elseJump = emitJump(OP_JUMP); // 生成无条件跳跃字节码patchJump(thenJump); // 计算并回填跳跃距离emitByte(OP_POP);if(match(TOKEN_ELSE)) // 如果 else 存在,解析其分支语句statement();patchJump(elseJump); // 计算并回填跳跃距离}
3.6.2 while 循环
OP_JUMP 配合负数参数也可以实现向后跳跃。不过字节码指令及其参数在虚拟机内部都使用 uint8_t 类型存储,故此处不使用负数以防诸多麻烦。
var a = 5;while(a > 0) {a = a - 1;}
0000 1 OP_CONSTANT 1 '5'0002 | OP_DEFINE_GLOBAL 0 'a'0004 2 OP_GET_GLOBAL 2 'a'0006 | OP_CONSTANT 3 '0'0008 | OP_GREATER // 判断 a 是否大于 00009 | OP_JUMP_IF_FALSE 9 -> 24 // 如果判定为假,跳过整个循环体0012 | OP_POP0013 3 OP_GET_GLOBAL 5 'a'0015 | OP_CONSTANT 6 '1'0017 | OP_SUBTRACT0018 | OP_SET_GLOBAL 4 'a'0020 | OP_POP0021 4 OP_LOOP 21 -> 4 // 跳回到 0004 处,再次进行条件判定0024 | OP_POP
static void whileStatement() {consumeToken(TOKEN_LEFT_PAREN, "需要左括号"); // 完成左括号解析,不存在则报错expression(); // 解析括号中的条件表达式consumeToken(TOKEN_RIGHT_PAREN, "需要右括号");int exitJump = emitJump(OP_JUMP_IF_FALSE); // 生成跳出循环体的条件跳跃字节码emitByte(OP_POP);statement(); // 解析循环体中语句emitLoop(loopStart); // 生成跳回字节码 OP_LOOPpatchJump(exitJump); // 回填跳跃的距离参数emitByte(OP_POP);}
3.6.3 for 循环
for(var i=0; i<5; i=i+1) {print i;}
0000 1 OP_CONSTANT 0 '0' // 生成字面量 00002 | OP_GET_LOCAL 1 // 获取序号 1 处局部变量值,即 i 的值0004 | OP_CONSTANT 1 '5' // 生成字面量 50006 | OP_LESS // 判断是否小于 50007 | OP_JUMP_IF_FALSE 7 -> 31 // 如果为假,跳过循环体0010 | OP_POP0011 | OP_JUMP 11 -> 25 // 无条件跳到 0025 处,跳过更新部分,循环体执行之后才执行这里0014 | OP_GET_LOCAL 10016 | OP_CONSTANT 2 '1'0018 | OP_ADD // 将序号 1 处局部变量,即 i 的值加10019 | OP_SET_LOCAL 10021 | OP_POP0022 | OP_LOOP 22 -> 2 // 跳回到 0002 处进行条件判定0025 2 OP_GET_LOCAL 1 // 执行循环体内逻辑0027 | OP_PRINT // 打印变量值0028 3 OP_LOOP 28 -> 14 // 执行完循环体后,跳回到 0014 处,执行 i=i+1 更新部分逻辑0031 | OP_POP0032 | OP_POP
static void forStatement() {consumeToken(TOKEN_LEFT_PAREN, "需要左括号"); // 完成左括号解析,不存在则报错// 初始化部分if(match(TOKEN_SEMICOLON)) { // for(;...) 形式,空初始化,无需操作} else if(match(TOKEN_VAR)) { // for(var i=0;...) 形式,声明新的循环变量 ivarDeclaration();} else { // for(i=0;...) 形式,直接使用外界的变量 i;或者是只需要其副作用的任意表达式expressionStatement();}// 条件部分...int exitJump = -1;if(!match(TOKEN_SEMICOLON)) { // 不是分号,条件部分不为空...exitJump = emitJump(OP_JUMP_IF_FALSE); // 如果假,跳出循环体...}// 更新部分if(!match(TOKEN_RIGHT_PAREN)) { // 不是右括号,更新部分不为空int bodyJump = emitJump(OP_JUMP); // 无条件跳到循环体部分...emitLoop(loopStart); // 执行完更新之后跳回到条件判定处loopStart = ...;patchJump(bodyJump);}statement(); // 解析循环体中语句emitLoop(loopStart); // 跳回到更新部分去执行if(exitJump != -1) {patchJump(exitJump); // 回填跳跃的距离参数emitByte(OP_POP);}}
3.6.4 逻辑与和或
if(true and true) { // 为了样例简便,矫揉造作了这里的写法print "AND is ok";}
0000 1 OP_TRUE0001 | OP_JUMP_IF_FALSE 1 -> 6 // 如果假,跳到 0006。此处真,不跳。0004 | OP_POP0005 | OP_TRUE0006 | OP_JUMP_IF_FALSE 6 -> 16 // 如果假,跳到 0016。此处真,不跳。0009 | OP_POP0010 2 OP_CONSTANT 0 'AND is ok'0012 | OP_PRINT // 正常执行打印0013 3 OP_JUMP 13 -> 170016 | OP_POP
if(false and true) {print "shortcut";}
0000 1 OP_FALSE0001 | OP_JUMP_IF_FALSE 1 -> 6 // 如果假,跳到 0006。此处假,跳。0004 | OP_POP0005 | OP_TRUE0006 | OP_JUMP_IF_FALSE 6 -> 16 // 0004 和 0005 处的操作被跳过,目前栈顶值还是假,跳到 00160009 | OP_POP0010 2 OP_CONSTANT 0 'shortcut'0012 | OP_PRINT0013 3 OP_JUMP 13 -> 170016 | OP_POP // 打印操作被跳过
static void andOperator(){int endJump = emitJump(OP_JUMP_IF_FALSE); // 生成跳跃字节码emitByte(OP_POP); // 左边值出栈... // 继续解析右边的表达式,可能有 a and b and c and d 的情况patchJump(endJump); // 回填跳跃的距离参数}
if(true or false) {print "shortcut";}
0000 1 OP_TRUE0001 | OP_JUMP_IF_FALSE 1 -> 7 // 如果假,跳到 0007。此处真,不跳。0004 | OP_JUMP 4 -> 9 // 直接跳到 00090007 | OP_POP0008 | OP_FALSE0009 | OP_JUMP_IF_FALSE 9 -> 19 // 0007 和 0008 处的操作被跳过,目前栈顶值还是真,不跳0012 | OP_POP0013 2 OP_CONSTANT 0 'shortcut'0015 | OP_PRINT // 正常执行打印0016 3 OP_JUMP 16 -> 200019 | OP_POP
static void orOperator(){int elseJump = emitJump(OP_JUMP_IF_FALSE); // 如果假,跳到 or 右边第一个值处继续判定int endJump = emitJump(OP_JUMP); // 如果真,跳过整个判定条件表达式patchJump(elseJump); // 回填 or 左边值判定假后跳跃的距离参数emitByte(OP_POP); // 左边值出栈... // 继续解析右边的表达式patchJump(endJump); // 回填跳跃整个条件表达式的距离参数}
3.7 函数
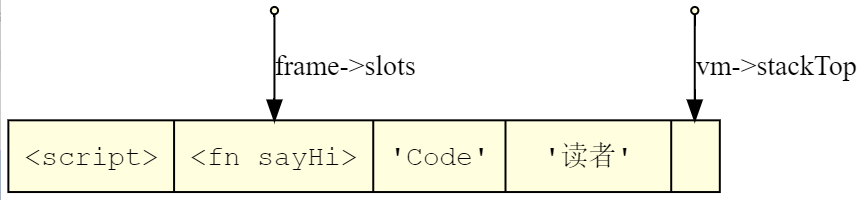
fn sayHi(first, last) {print "Hi, " + first + " " + last + "!";}sayHi("Code", "读者");
== sayHi == // sayHi 函数体0000 2 OP_CONSTANT 0 'Hi, ' // 构建字面常量0002 | OP_GET_LOCAL 1 // 获取序号 1 处局部变量,即第一个参数 first0004 | OP_ADD // 字符串拼接0005 | OP_CONSTANT 1 ' ' // 构建字面常量0007 | OP_ADD // 字符串拼接0008 | OP_GET_LOCAL 2 // 获取序号 2 处局部变量,即第二个参数 last0010 | OP_ADD // 字符串拼接0011 | OP_CONSTANT 2 '!' // 构建字面常量0013 | OP_ADD // 字符串拼接0014 | OP_PRINT // 打印0015 3 OP_NIL0016 | OP_RETURN // 该函数没有明确返回值,故默认返回值为 nil== <script> == // 脚本主体0000 3 OP_CLOSURE 1 <fn sayHi> // 构建函数0002 | OP_DEFINE_GLOBAL 0 'sayHi' // sayHi 函数加入到全局表0004 5 OP_GET_GLOBAL 2 'sayHi' // 从全局表中获取 sayHi 函数0006 | OP_CONSTANT 3 'Code' // 构建字面常量0008 | OP_CONSTANT 4 '读者' // 构建字面常量0010 | OP_CALL 2 // 调用 sayHi 函数0012 | OP_POP // 弹出栈顶值
case OP_CLOSURE: {ObjFunctioin *function = AS_FUNCTION(READ_CONSTANT()); // 根据序号读出函数对象ObjClosure *closure = newClosure(function); // 构建闭包对象push(OBJ_VAL(closure)); // 将 sayHi 函数压入值栈,供后面的 OP_DEFINE_GLOBAL 指令使用...break;}
static void function(FunctionType type){...consumeToken(TOKEN_LEFT_PAREN, "需要左括号");if (!check(TOKEN_RIGHT_PAREN)) // 如果没有遇到右括号,解析参数{do{... // 解析函数形式参数} while (match(TOKEN_COMMA));// 如果遇到逗号,继续解析下一个参数}consumeToken(TOKEN_RIGHT_PAREN, "需要右括号");consumeToken(TOKEN_LEFT_BRACE, "需要左花括号");block(); // 解析函数体ObjFunction *function = ...; // 构建函数对象emitBytes(OP_CLOSURE, makeConstant(OBJ_VAL(function))); // 生成 OP_CLOUSRE 字节码指令...}
case OP_CALL: {int argCount = READ_BYTE(); // 获取函数参数个数if(!call_(peek(argCount), argCount)) { // 调用 call_ 完成调用逻辑,peek(argCount) 是指栈顶往下 argCount 个位置的函数对象return RUNTIME_ERROR; // 失败则报运行时错误}frame = &vm.frames[vm.frameCount - 1]; // 成功完成,重新指向栈顶下方的函数调用栈帧break;}
static bool call_(ObjClosure *closure, int argCount) //如前文所述,ObjClosure 就是封装后的 ObjFunction{if (argCount != closure->function->arity) { // 检查参数个数,不匹配则打回runtimeError("需要 %d 个参数,提供了 %d 个", closure->function->arity, argCount);return false;}// 调用层数超出限制,给出经典的 Stack Overflow 错误if (vm.frameCount == FRAMES_MAX) {runtimeError("栈溢出");return false;}// 构建调用栈帧,压入调用栈CallFrame *frame = &vm.frames[vm.frameCount++];frame->closure = closure;// ip 即 instruction pointer 指令指针,指向函数体内字节码,比如上文中 sayHi 函数的字节码frame->ip = closure->function->chunk.code;// 函数调用所需参数列表指向虚拟机值栈对应位置frame->slots = vm.stackTop - argCount - 1;return true;}
typedef struct {ObjClosure *closure; // 闭包对象uint8_t *ip; // 指向当前指令的指令指针 Instruction Pointer,有些语言里会称作 Program Counter (PC)Value *slots; // 参数列表指针} CallFrame;
fn adder(operand) {if(operand <= 0) {return 0;}return operand + adder(operand - 1);}print adder(5);
== adder ==0000 2 OP_GET_LOCAL 10002 | OP_CONSTANT 0 '0'0004 | OP_GREATER0005 | OP_NOT // operand <= 0 等价于 !(operand > 0)0006 | OP_JUMP_IF_FALSE 6 -> 16 // 未达到基准条件,跳到 00160009 | OP_POP0010 3 OP_CONSTANT 1 '0'0012 | OP_RETURN0013 4 OP_JUMP 13 -> 170016 | OP_POP0017 5 OP_GET_LOCAL 10019 | OP_GET_GLOBAL 2 'adder'0021 | OP_GET_LOCAL 10023 | OP_CONSTANT 3 '1'0025 | OP_SUBTRACT // 当前参数减 1 后的值放入栈顶0026 | OP_CALL 1 // 再次发起调用,即再压入一个 CallFrame0028 | OP_ADD // 将当前参数与调用产生的值相加0029 | OP_RETURN== <script> ==0000 6 OP_CLOSURE 1 <fn adder>0002 | OP_DEFINE_GLOBAL 0 'adder' // 定义这个全局函数0004 8 OP_GET_GLOBAL 2 'adder'0006 | OP_CONSTANT 3 '5'0008 | OP_CALL 10010 | OP_PRINT
3.8 闭包
== myFunc ==0000 4 OP_GET_UPVALUE 0 // 获取被闭包的参数0002 | OP_PRINT // 打印0003 5 OP_NIL0004 | OP_RETURN== makeFunc ==0000 2 OP_CONSTANT 0 'hello'0002 5 OP_CLOSURE 1 <fn myFunc> // 生成闭包函数,并携带闭包参数0004 | local 1 // myFunc 携带的闭包参数是从父函数的局部变量捕获所得,即脚本中的 a0006 6 OP_GET_LOCAL 2 // myFunc 是内部函数,所以也是 local0008 | OP_RETURN== <script> ==0000 7 OP_CLOSURE 1 <fn makeFunc> // 生成函数0002 | OP_DEFINE_GLOBAL 0 'makeFunc'0004 9 OP_GET_GLOBAL 3 'makeFunc'0006 | OP_CALL 00008 | OP_DEFINE_GLOBAL 2 'f'0010 10 OP_GET_GLOBAL 4 'f'0012 | OP_CALL 0 // 调用 f 函数0014 | OP_POP
获取闭包参数的指令叫作 OP_GET_UPVALUE,这里是借鉴了 Lua 作者的叫法。Lua 内部将实现闭包的数据结构称为 Upvalue 。
case OP_CLOSURE: {...ObjClosure *closure = newClosure(function);push(OBJ_VAL(closure));for(...) {...if(isLocal) {closure->upvalues[i] = captureUpvalue(...); // 捕获潜在闭包参数} else {...}}...}static ObjUpvalue *captureUpvalue(Value *local) {...ObjUpvalue *upvalue = vm.openUpvalues;...ObjUpvalue *newUpvalue = newUpvalue(local);newUpvalue->next = upvalue;...vm.openUpvalues = newUpvalue;...}
case OP_RETURN: {...closeUpvalues(frame->slots);...}static void closeUpvalues(Value *last){// 在 frame->slots 之后的变量全部搬到堆上while (vm.openUpvalues != NULL && vm.openUpvalues->location >= last){ObjUpvalue *upvalue = vm.openUpvalues;upvalue->closed = *upvalue->location; // 原本栈上的值拷贝到 closed 字段中,也就到了堆上upvalue->location = &upvalue->closed; // 指针位置指向 closed 字段vm.openUpvalues = upvalue->next;}}
typedef struct ObjUpvalue{Obj obj; // 元信息头部Value *location; // 记录该变量原本在栈上的位置Value closed; // 如果该变量被闭包,将 location 指向的值拷贝到此处。即从栈上搬到堆上,保证其长期存活struct ObjUpvalue *next; // 链表指针} ObjUpvalue;
if arg = resolveLocal(current, &name);if(arg != -1) { // 找到了局部变量,生成 OP_GET_LOCAL 字节码...} else if(arg = resolveUpvalue(current, &name)) != -1) { // 找到了闭包参数,生成 OP_GET_UPVALUE 字节码emitBytes(OP_GET_UPVALUE, arg);} else { // 当作全局变量处理,生成 OP_GET_GLOBAL,如果还是没有就报“未定义”错误...}
static int resolveUpvalue(Token *name) {...int local = resolveLocal(parent, name); // 先尝试从父作用域的局部变量中找if(local != -1) {return addUpvalue(...); // 记录下闭包参数,下同}int upvalue = resolveUpvalue(parent, name); // 如果没找到,再从父作用域的闭包参数中找,递归调用到顶为止if(upvalue != -1) {return addUpvalue(...);}return -1; // 找不到则返回}
如上代码所示,addUpvalue 函数既可用于将父作用域的局部变量加入到当前作用域闭包参数中,也可用于将父作用域“继承”而来的闭包参数加入到当前作用域闭包参数中。
本例中,myFunc 没找到局部变量 a,但找到了闭包参数 a。所以,它生成了 OP_GET_UPVALUE 字节码指令。虚拟机执行 OP_GET_UPVALUE 指令时会从闭包函数对象的 upvalues 列表中获取对应的闭包参数。
case OP_GET_UPVALUE: {uint8_t slot = READ_BYTE();push(*frame->closure->upvalues[slot]->location);break;}
3.9 面向对象
class Cake {eat() { // 定义成员函数 eatvar adjective = "好吃";print "这个" + this.flavor + "蛋糕真" + adjective + "!";}}var cake = Cake();cake.flavor = "巧克力"; // 动态地设置实例字段cake.eat(); // 输出“这个巧克力蛋糕真好吃!”
3.9.1 类与实例
0000 1 OP_CLASS 0 'Cake' // 定义 Cake 类0002 | OP_DEFINE_GLOBAL 0 'Cake' // 加到全局表0004 | OP_GET_GLOBAL 1 'Cake'...0010 6 OP_POP0011 8 OP_GET_GLOBAL 5 'Cake'0013 | OP_CALL 0 // 调用 Cake(),因为 Cake 未指定构造函数,故使用默认的无参构造函数0015 | OP_DEFINE_GLOBAL 4 'cake' // 加到全局表0017 9 OP_GET_GLOBAL 6 'cake'...
static void classDeclaration() {consumeToken(TOKEN_IDENTIFER, "需要类名");...emitBytes(OP_CLASS, ...); // 生成 OP_CLASS 字节码...if(match(TOKEN_COLON)) { // 如果有冒号符号,尝试解析父类...}namedVariable(className, ...); // 生成 OP_DEFINE_GLOBAL,加入到全局表,这样可以允许成员方法引用该类consumeToken(TOKEN_LEFT_BRACE, "需要左花括号");while (!check(TOKEN_RIGHT_BRACE) && !check(TOKEN_EOF)){method(); // 在遇到右花括号之前,循环解析成员方法}consumeToken(TOKEN_RIGHT_BRACE, "需要右花括号");...}
case OP_CLASS: {ObjString *name = READ_STRING();ObjClass *klass = ALLOCATE_OBJ(ObjClass, OBJ_CLASS); // 初始化结构体klass->name = name;initTable(&klass->methods); // 初始化类成员方法表push(OBJ_VAL(klass)); // 压入值栈,方便后续调用break;}
typedef struct{Obj obj; // 元信息ObjString *name; // 类名Table methods; // 成员方法表} ObjClass;
...0017 9 OP_GET_GLOBAL 6 'cake' // 获得 cake 实例0019 | OP_CONSTANT 8 '巧克力'0021 | OP_SET_PROPERTY 7 'flavor' // 设置 cake 实例的属性...
case OP_SET_PROPERTY: {if(!IS_INSTANCE(peek(1)) { // 只有类的实例才可以动态设置字段runtimeError("只有实例才允许字段赋值");return RUNTIME_ERROR;}ObjInstance *instance = AS_INSTANCE(peek(1)); // 获得实例对象tableSet(&instance->fields, READ_STRING(), ...); // 设置其字段表的值...break;}
typedef struct{Obj obj; // 元信息ObjClass *klass; // 所属的类Table fields; // 字段表} ObjInstance;
0024 10 OP_GET_GLOBAL 9 'cake' // 从全局表中获得 cake 实例0026 | OP_INVOKE (0 args) 10 'eat' // 调用成员方法 eat,携带 0 个参数
case OP_INVOKE: {ObjString *method = READ_STRING(); // 获得方法名int argCount = READ_BYTE(); // 获取参数个数if(!invoke(method, argCount)) { // 发起调用return RUNTIME_ERROR;}frame = &vm.frames[vm.frameCount - 1]; // 成功完成,重新指向栈顶下方的函数调用栈帧break;}static bool invoke(ObjString *name, int argCount) {Value receiver = peek(argCount); // 获得实例对象...ObjInstance *instance = AS_INSTANCE(receiver); // 转成具体类型...ObjClass *klass = instance->class;Value method;if(!tableGet(&klass->method, name, &method)) { // 从实例关联的类中查找成员方法runtimeError("未定义属性 '%s'", name->chars);return false;}return call_(AS_CLOSURE(method), argCount); // 包装成闭包对象,像普通函数一样调用}
3.9.2 成员方式
0024 10 OP_GET_GLOBAL 9 'cake' // 从全局表中获得 cake 实例0026 | OP_INVOKE (0 args) 10 'eat' // 调用成员方法 eat,携带 0 个参数
case OP_METHOD: {ObjString *name = READ_STRING();Value method = peek(0); // 获得栈顶已经包装好成员方法的闭包对象ObjClass *klass = AS_CLASS(peek(1)); // 获取栈顶下方的 Cake 类tableSet(&klass->methods, name, method); // 把闭包对象加入到类的 `methods` 表中,如果 name 已经存在,覆盖旧值pop(); // 弹出栈顶元素break;}
static void method() {consumeToken(TOKEN_IDENTIFIER, "需要方法名");...if(token.length == 4 && memcmp(token.name, "init", 4) == 0) {// 如果成员方法名为 "init",表示是构造函数,走特殊逻辑...}// 同前文普通函数解析方法...emitBytes(OP_ClOSURE, ...); // 生成 OP_CLOSURE 字节码emitBytes(OP_METHOD, ...); // 生成 OP_METHOD 字节码}
3.9.3 构造函数
class Cake {init(color) {this.color = color; // 设置 color 字段}eat() {print "这个" + this.color + "蛋糕真不错!";}}var cake = Cake("粉色");cake.eat();
== init ==0000 3 OP_GET_LOCAL 0 // 获得序号 0 的局部变量,即 this,此位置专门预留给 this0002 | OP_GET_LOCAL 1 // 获得序号 1 的局部变量,即 color 参数0004 | OP_SET_PROPERTY 0 'color' // 将参数赋值到 this 的属性 color 中0006 | OP_POP0007 4 OP_GET_LOCAL 0 // 获得序号 0 的局部变量,即this0009 | OP_RETURN // 返回 this,即实例自身== eat ==0000 7 OP_CONSTANT 0 '这个'0002 | OP_GET_LOCAL 0 // 获得序号 0 的局部变量,即this0004 | OP_GET_PROPERTY 1 'color' // 获得 this 上的属性字段 color0006 | OP_ADD // 字符串拼接0007 | OP_CONSTANT 2 '蛋糕真不错!'...== <script> ==0000 1 OP_CLASS 0 'Cake'0002 | OP_DEFINE_GLOBAL 0 'Cake'0004 | OP_GET_GLOBAL 1 'Cake'0006 4 OP_CLOSURE 3 <fn init> // 生成构造函数包装而成的闭包对象0008 | OP_METHOD 2 'init' // 构造函数加入到类的成员方法表...
static void retrunStatement() {...if(current->type == TYPE_INITIALIZER) {error("不可以在构造函数内使用 return。");}...}
如前所述,eben 中普通函数在没有指定返回值的情况下,会默认返回空值 nil 。所以,编译器解析 eben 函数过程中调用 emitReturn 时需要对两种情况分别处理。
static void emitReturn() {if(current->type == TYPE_INITIALIZER) { // 是构造函数emitBytes(OP_GET_LOCAL, 0); // this 处在局部变量预留位置 0} else { // 是普通函数emitByte(OP_NIL);}emitByte(OP_RETURN); // 生成返回操作字节码}
3.9.4 构造函数
class Cake {eat() {print "这个蛋糕真好吃!";}make() {print "做蛋糕很辛苦.";}}class BananaCake : Cake { // BananaCake 继承 Cakeeat() { // 覆盖父类同名方法super.eat(); // 调用父类的方法print "加了香蕉更好吃!";}}var bc = BananaCake(); // 构建实例bc.make(); // 调用继承而来的方法 make,输出“做蛋糕很辛苦.”bc.eat(); // 调用覆盖方法 eat,输出“这个蛋糕真好吃!\n加了香蕉更好吃!”
== eat == // Cake 中 eat 方法...== make == // Cake 中 make 方法...== eat ==0000 13 OP_GET_LOCAL 0 // 获得 this0002 | OP_GET_UPVALUE 0 // 获得 super0004 | OP_SUPER_INVOKE (0 args) 0 'eat' // 调用父类方法 eat0007 | OP_POP0008 14 OP_CONSTANT 1 '加了香蕉更好吃!'0010 | OP_PRINT0011 15 OP_NIL0012 | OP_RETURN== <script> ==0000 1 OP_CLASS 0 'Cake' // 生成父类 Cake... // 生成父类 Cake 成员方法0015 11 OP_CLASS 6 'BananaCake' // 生成子类 BananaCake0017 | OP_DEFINE_GLOBAL 6 'BananaCake'0019 | OP_GET_GLOBAL 7 'Cake'0021 | OP_GET_GLOBAL 8 'BananaCake'0023 | OP_INHERIT // 继承父类的方法(只继承方法,不继承字段,因为后者都是动态设置)0024 | OP_GET_GLOBAL 9 'BananaCake' // 开始生成其成员方法... // OP_METHOD 指令,此处略去0033 | OP_CLOSE_UPVALUE0034 18 OP_GET_GLOBAL 13 'BananaCake'0036 | OP_CALL 0 // 调用默认构造函数0038 | OP_DEFINE_GLOBAL 12 'bc'0040 19 OP_GET_GLOBAL 14 'bc'0042 | OP_INVOKE (0 args) 15 'make' // 调用继承来的 make 方法0045 | OP_POP0046 20 OP_GET_GLOBAL 16 'bc'0048 | OP_INVOKE (0 args) 17 'eat' // 调用 eat 方法...
...ObjClass *superclass = AS_CLASS(pop()); // pop() 出来的参数是事先放置的父类if(!invokeFromClass(superclass, method, argcount)) {return RUNTIME_ERROR;}...
uint8_t argCount = argumentList(); // 解析函数参数,返回参数个数namedVariable("super", ...); // 通过 resolveLocal, resolveUpvalue 查找逻辑找到闭包参数 superemitBytes(OP_SUPER_INVOKE, name); // 生成 OP_SUPER_INVOKE 指令,本例中 name 就是 "eat" 函数对象的序号emitByte(argCount); // 生成参数个数
static void classDeclaration() {...if(match(TOKEN_COLON)) { // 遇到冒号,有继承父类关系,当前类是一个子类consumeToken(TOKEN_IDENTIFIER, "需要父类名称.");variable(false); // 获取父类,压入值栈...addLocal("super"); // super 加到局部变量列表,让其被闭包捕获,方便子类方法引用defineVariable(0);...}...}
case OP_INHERIT: {Value superclass = peek(1);...ObjClass *subclass = AS_CLASS(peek(0));// 将父类方法表拷贝到子类方法表tableAddAll(&AS_CLASS(superclass)->methods, &subclass->methods);pop(); // 弹出子类break;}
static void classDeclaration() {...if(match(TOKEN_COLON)) { // 遇到冒号,有继承父类关系...namedVariable(className, ...); // 生成 OP_GET_GLOBAL 指令,加载 BananaCake 类进栈emitByte(OP_INHERIT); // 生成继承指令}...}
3.10 垃圾回收
开发过程中,总要有人操心内存管理。要么是语言使用者(比如 C/C++ 使用者和 ARC 出现之前的 Obj-C 使用者),要么是语言作者(比如 Java、Python、C#、Go 的作者)。eben 带有 Garbage Collection 垃圾自动回收特性(简称 GC) ,所以 eben 使用者比较幸运,不需要操心内存管理。
如前文所介绍,eben 脚本语言中的函数、闭包参数、闭包、类、实例、绑定方法等等都有其对应的底层类型,大致结构如下所示:
typedef struct{Obj obj; // 元信息...ObjY *someObject; // 可能包含任意个对其他复杂类型的引用Table someTable; // 可能包含自定义的哈希表结构体char *chars; // 可能包含字符串指针} ObjX;
虚拟机中通过 freeObject 函数来释放这些底层类型的内存。
void freeObject(Obj *object) {swtich(object->type) {case OBJ_CLASS: { // 类对象ObjClass *klass = (ObjClass *)object;freeTable(&klass->methods); // 释放其方法表FREE(ObjClass, object); // 释放结构自身break;}...case OBJ_STRING: { // 字符串对象ObjString *string = (ObjString*)object;FREE_ARRAY(char, string->chars, string->length+1); // 尾部的'\0'也一起释放FREE(ObjString, object); // 释放结构自身break;}...}}
其他底层类型的释放逻辑与上面二者大同小异。理论上,只要虚拟机能够将所有需要释放的对象归置到一起,再全部释放,就可以避免内存泄漏,也就可以管理好内存。为了判断对象是否需要释放,eben 在每一个底层类型头部都嵌套了 Obj obj 字段。该字段中内含的 isMarked 布尔字段被用来判断对象是否该释放。
struct Obj {ObjType type; // OBJ_CLASS, OBJ_FUNCTION, OBJ_STRING 等等枚举值bool isMarked; // 是否被标记struct Obj *next; // 链接串接指针}
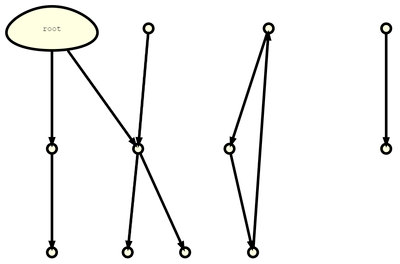
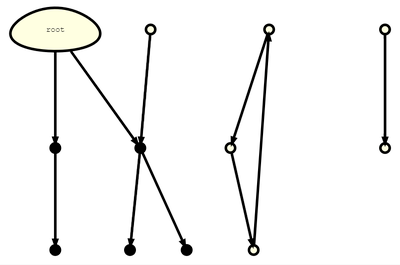
看到 isMarked 字段,读者大概已经猜到 eben 中会使用 Mark-Sweep 方法来清理内存。业界有很多高级垃圾回收算法来高效地完成回收,本文为了简便使用了最朴素但是也蛮高效的 Mark-Sweep 标记清除方法。其主要流程如下表所示:
| 初始状态 | 标记 Mark | 清除 Sweep |
 |
 |
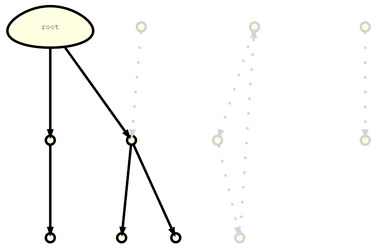 |
| 存在引用无法可达的对象 | 将 root 出发引用可达的对象标记成黑色 | 将未标记的对象清除 |
void gc() {markRoots(); // 虚拟机主结构直接引用的对象称为 root,将其全部标记markByReferences(); // 从 root 出发,根据引用关系在所有对象中访问扩散并标记sweep(); // 清除所有没被标记过的对象...}
static void markRoots() {for(Value *slot = vm.stack; slot < vm.stackTop; slot++) {markValue(*slot);}... // 其他直接引用的对象markTable(&vm.globals);markObject((Obj *)vm.initString);...}
void markObject(Obj *object) {...if(object->isMarked)return; // 已经标记过,返回object->isMarked = true; // 标记...vm.grayStack[vm.grayCount++] = object; // 加入到已访问节点栈中}
static void markByReferences() {while(vm.grayStack > 0) { // 取出节点访问栈中全部对象为止Obj *object = vm.grayStack[--vm.grayCount];switch(object->type) {...case OBJ_CLASS: { // 按类型标记类对象ObjClass *klass = (ObjClass *)objects;markObject((Obj *)klass->name); // 标记 Class 中引用的名称字段 namemarkTable(&klass->methods); // 标记 Class 中引用的方法表字段 methodsbreak;}case OBJ_FUNCTION: { // 按类型标记函数对象ObjFunction *func = (ObjFunction *)object;markObject((Obj *)func->name); // 标记 Function 中引用的名称字段 namemarkArray(&func->chunk.constants); // 标记 Function 中引用的常量表字段 constantsbreak;}... // 其他需要标记其字段的对象}}}
static void sweep() {Obj *prev = NULL;Obj *object = vm.objects; // vm.objects 链表中维护系统分配出来的所有对象,它不参与 markRootswhile(object != NULL) {if(!object->isMarked) {Obj *garbage = object; // 锁定垃圾对象// 链表删除节点处理object = object->next;if(prev != NULL) {previous->next = object;} else {vm.objects = object;}freeObject(garbage); // 清除垃圾对象}... // 其他维护工作}}
static Obj *allocateObject(size_t size, ObjType type) {Obj *object = (Obj *)custom_allocate(NULL, 0, size); // 使用自定义的内存分配函数...object->next = vm.objects; // 加入到链表头位置vm.objects = object;...}
void *custom_allocate(void *pointer, size_t oldSize, size_t newSize) { // 所有新对象的生成对会用到此函数vm.bytesAllocated += newSize - oldSize;if(vm.bytesAllocated > vm.nextGC) { // 大于阈值,发起 gcgc();}...}
void gc() {...vm.nextGC = vm.bytesAllocated * GC_GROW_FACTOR;}
至此,一个完整的垃圾回收机制就完成了。

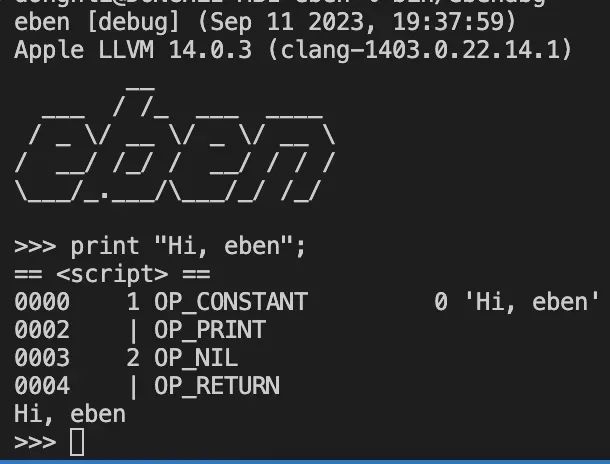
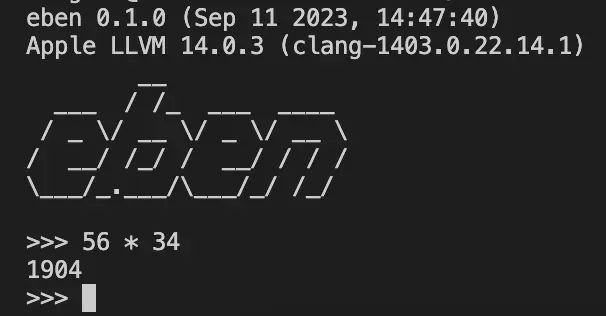
了解完 eben 的内在之后,想必读者再看到这个 REPL 会更感亲切,也更感透彻。
笔者在学习完 Robert Nystrom 的 "Crafting Interpreters" 全书和 Roberto Ierusalimschy 的 Lua 设计论文后,就对编译原理有了远比之前更透彻的理解。既钦佩于作者才华之美,又感叹他们计算机教育水平之高。基于前文的编程语言诞生时间表,笔者又理了一份编程语言作者表,方便读者直观地感受他们的编译原理发展水平之高。
| 年份 | 语言 | 主要作者 | 国籍 |
| 1957 | FORTRAN | John Backus | 美国 |
| 1958 | LISP | John McCarthy | 美国 |
| 1970 | Pascal | Niklaus Wirth | 瑞士 |
| 1972 | C | Dennis Ritchie | 美国 |
| 1978 | SQL | Donald D. Chamberlin, Raymond F. Boyce | 美国 |
| 1980 | C++ | Bjarne Stroustrup | 丹麦 |
| 1986 | Objective-C | Brad Cox | 美国 |
| 1987 | Perl | Larry Wall | 美国 |
| 1990 | Python | Guido van Rossum | 荷兰 |
| 1993 | Lua | Roberto Ierusalimschy | 巴西 |
| 1995 | Ruby | 松本行弘 | 日本 |
| 1995 | Java | James Gosling | 加拿大 |
| 1995 | JavaScript | Brendan Eich | 美国 |
| 1995 | PHP | Rasmus Lerdorf | 加拿大 |
| 2001 | C# | Anders Hejlsberg | 丹麦 |
| 2003 | Scala | Martin Odersky | 德国 |
| 2009 | Go | Rob Pike, Ken Thompson 等 | 美国 |
| 2012 | TypeScript | Anders Hejlsberg | 丹麦 |
| 2014 | Swift | Chris Lattner | 美国 |
| 2015 | Rust | Graydon Hoare | 加拿大 |
| ... | ... | ... | ... |

📢📢欢迎加入腾讯云开发者社群,社群专享券、大咖交流圈、第一手活动通知、限量鹅厂周边能你来~
(长按图片立即扫码)





关注并星标腾讯云开发者
每周4看鹅厂程序员测评新技术