
我跟面试官说MySQL单表数据量不要超过两千万,面试官不信
云加社区
共 5495字,需浏览 11分钟
· 2023-09-20

👉导读
👉目录
于是小王以过往项目里的某个 case 为例做了回答:
我负责的项目里涉及到存储用户操作记录的功能,因为每天的数据量比较大,差不多超过 5000 万条,所以我另外又做了分库分表的操作。系统会自动定时生成 3 张表,数据分别存储其中,防止都放在一个表里面导致查询性能降低。
小王内心 OS:为什么1+1=2?但他还是语气平常地回答说:
MySQL 单表不要超过 2000 万行基本上是一个行业共识,只有当单表行数超过 500 万行或者单表容量超过 2GB,我们一般才推荐进行分库分表。
01
02
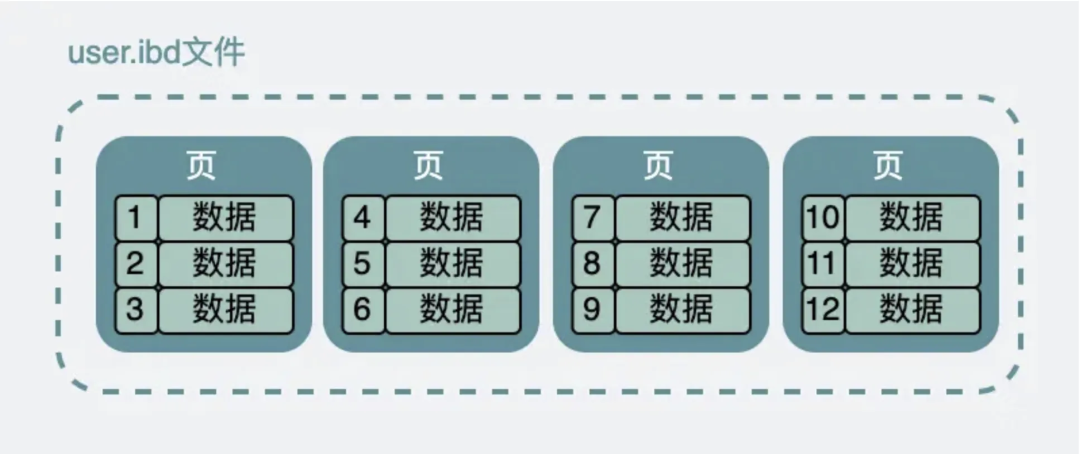

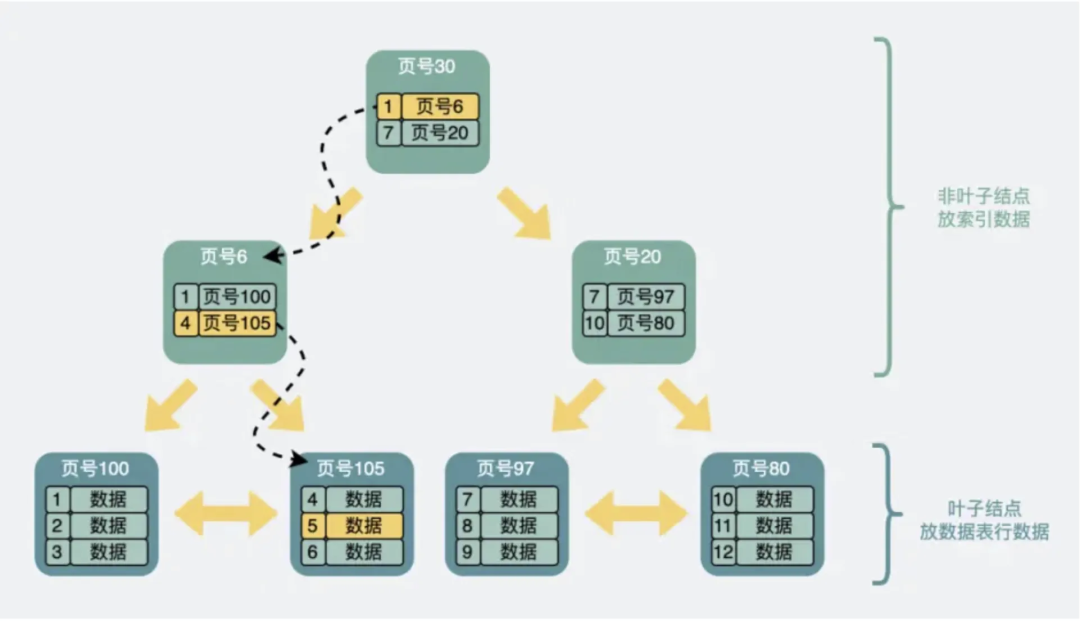

|
|
03






评论
面试官问:MySQL上亿大表,如何优化?
背景XX 实例(一主一从)xxx 告警中每天凌晨在报 SLA 报警,该报警的意思是存在一定的主从延迟。(若在此时发生主从切换,需要长时间才可以完成切换,要追延迟来保证主从数据的一致性)。XX 实例的慢查询数量最多(执行时间超过 1s 的 SQL 会被记录),XX 应用那方每天晚上在做删除一个月前数据
Java专栏
10