
MySQL VS PostgreSQL,谁是世界上最成功的数据库?
云加社区
共 8538字,需浏览 18分钟
· 2023-09-20
 # 关注并星标腾讯云开发者
# 关注并星标腾讯云开发者
# 每周1 | 鹅厂工程师带你审判技术
# 第5期 | 成江东:谁是世界上最成功的数据库?







事务内语句失败是否回滚
BEGIN;INSERT INTO t VAVLUES (1,...);INSERT INTO t VAVLUES (1,...); -- 主键冲突,报错COMMIT;
SELECT * FROM t;-- 得到1这条记录
开源协议
MVCC 实现机制
多进程 VS 多线程
-
PostgreSQL 采用多进程
-
MySQL 采用多线程
多进程 VS 多线程
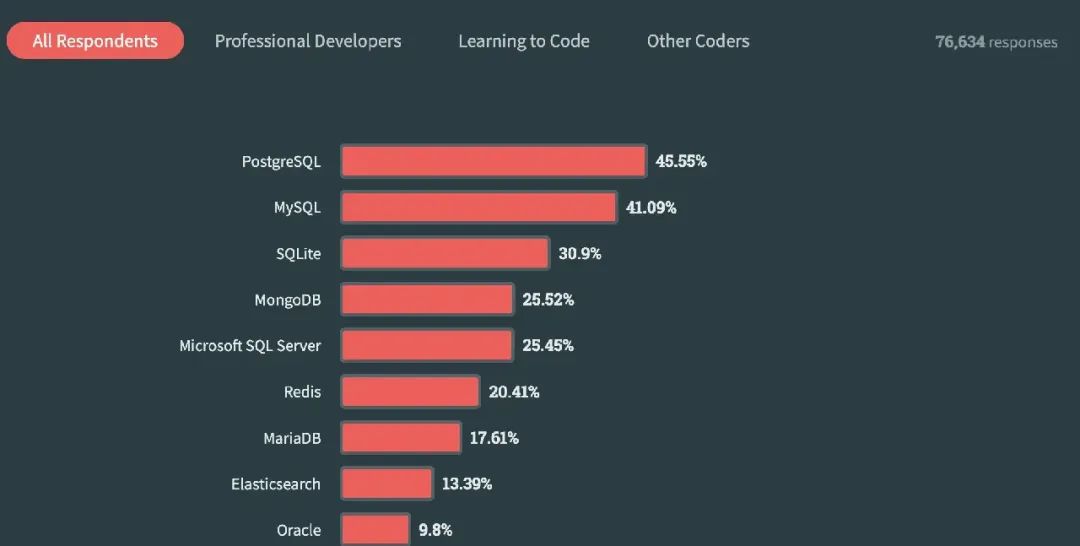
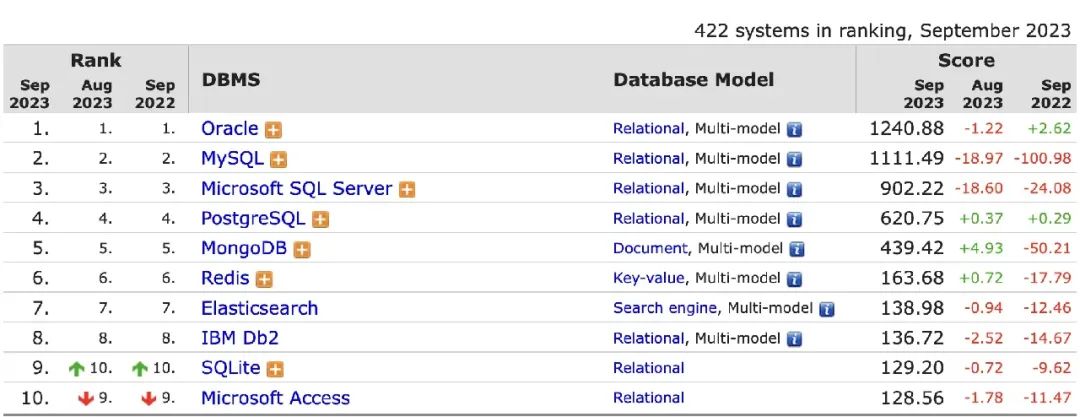
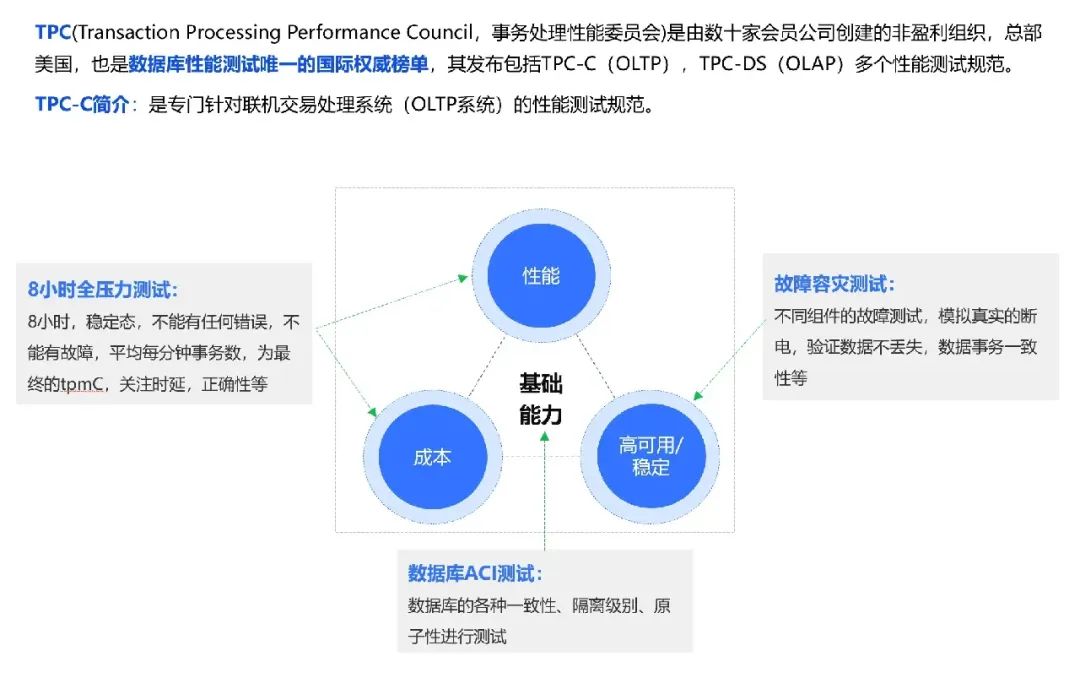
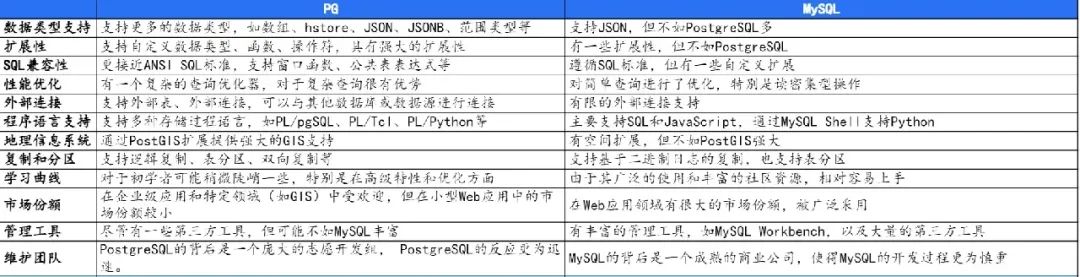
其它项目对比







评论
MySQL to PostgreSQL
MySQLtoPostgreSQL可以将简单的MySQLdump文件转成PostgreSQL格式,会自动在装载数据后才创建索引,数据的加载使用PostgreSQL的COPY命令字节从CSV文件中装载。
MySQL to PostgreSQL
0
DBConvert for MySQL & PostgreSQL数据库迁移工具
DBConvertforMySQL&PostgreSQL是一种可靠的双向定向数据库迁移工具,它可让您同步转换:MySQLtoPostgreSQLMySQLtoPostgreSQLDumpMyS
DBConvert for MySQL & PostgreSQL数据库迁移工具
0
EnterpriseDB基于 PostgreSQL 的数据库
EnterpriseDB是PostgreSQL的一个分支,在PostgreSQL基础上,针对企业级应用进行了专门的优化,同时,增加了一系列如动态性能调优(DynaTune)、EDBLoader、高效批
EnterpriseDB基于 PostgreSQL 的数据库
0
PostgreSQL数据库服务器
PostgreSQL(也叫Postgres)是一个自由的对象-关系数据库服务器(数据库管理系统),它在灵活的BSD-风格许可证下发行。它提供了相对其他开放源代码数据库系统(比如MySQL和Firebi
PostgreSQL数据库服务器
0
AgensSQL基于 PostgreSQL 的数据库
AgensSQL是一个基于PostgreSQL的数据库产品,保证了最佳的性能和稳定性。提供了标准版和企业版。使用AgensSQL的好处:降低TCO总拥有成本真正开源的数据库开发此产品的公司Bitnin
AgensSQL基于 PostgreSQL 的数据库
0